



📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2025/04/08/plaid/
原文作者:BAIR Blog

PLAID 是一种多模态生成模型,它通过学习蛋白质折叠模型的潜在空间,能够同时生成蛋白质的 1D 序列和 3D 结构。
2024年诺贝尔化学奖授予 AlphaFold2 的开发者,这标志着人工智能在生物学领域的作用得到了重要认可。那么,蛋白质折叠之后,下一步是什么?
在 PLAID 中,我们开发了一种能够学习采样蛋白质折叠模型潜在空间从而生成新蛋白质的方法。它支持组合功能提示词和物种提示词,并且可以在序列数据库上进行训练,这些数据库的规模比结构数据库大 2 到 4 个数量级。与以往许多蛋白质结构生成模型不同,PLAID 解决了多模态共同生成的问题:即同时生成离散的序列和连续的全原子结构坐标。
从结构预测到现实世界的药物设计
尽管最近的研究展示了扩散模型在生成蛋白质方面的潜力,但以往的模型仍存在一些局限性,使其难以在实际应用中落地:
- 全原子生成:许多现有的生成模型只生成骨架原子。要生成全原子结构并放置侧链原子,我们需要知道序列。这就构成了一个需要同时生成离散和连续模态的多模态生成问题。
- 物种特异性:用于人体的蛋白质生物制剂需要进行人源化,以避免被人类免疫系统破坏。
- 控制规范:药物发现和临床应用是一个复杂的过程。我们如何指定这些复杂的约束条件?例如,即使生物学问题解决了,你可能还需要考虑溶解度等新限制。
生成“有用”的蛋白质
仅仅生成蛋白质是不够的,更重要的是控制生成过程以获得有用的蛋白质。PLAID 通过组合约束来控制生成,最终目标是实现完全通过文本界面进行控制,目前已实现了基于功能和物种的双轴控制。
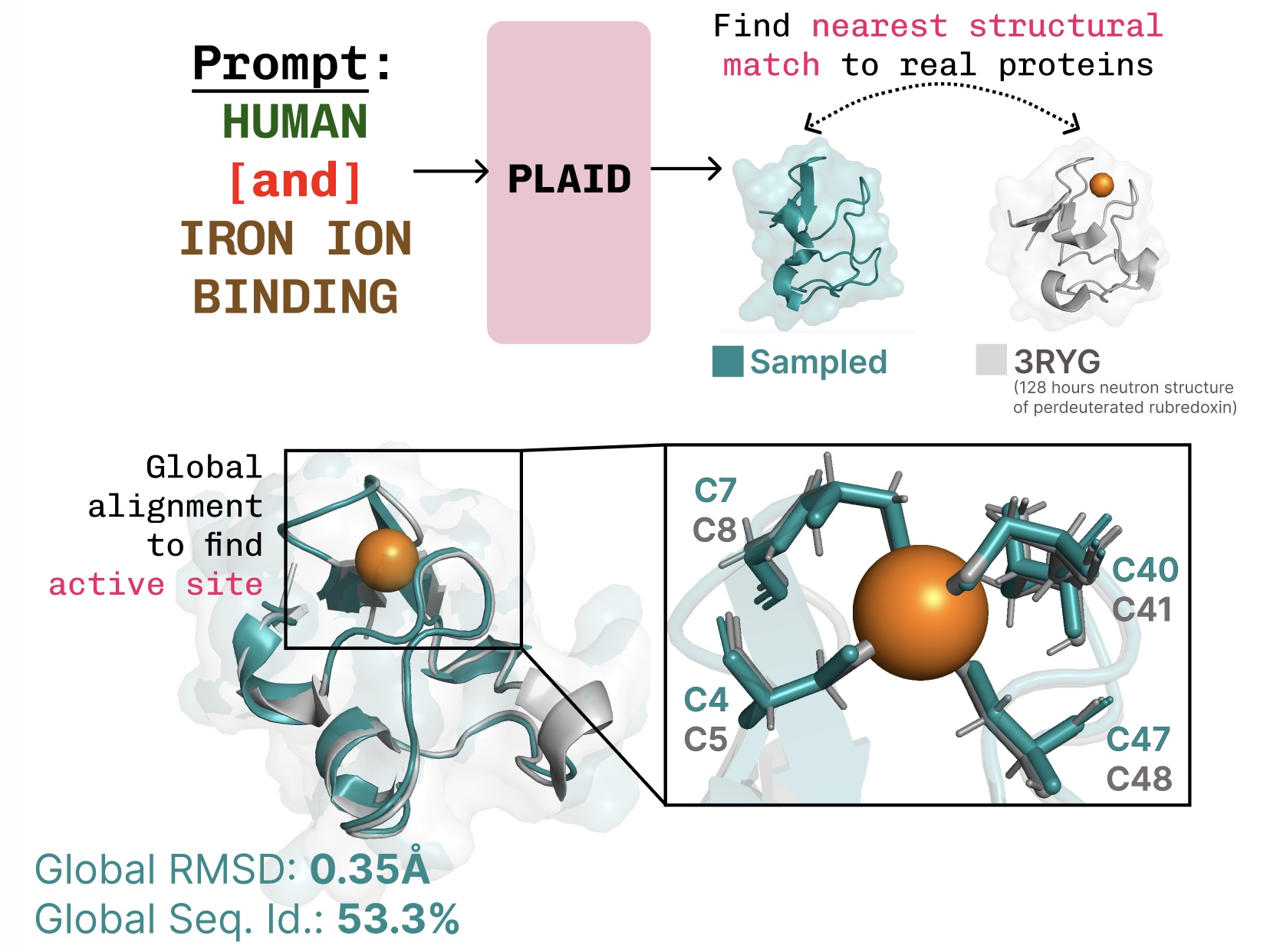
学习功能-结构-序列之间的联系。 PLAID 能够学习金属蛋白中常见的四面体半胱氨酸-Fe2+/Fe3+ 配位模式,同时保持高水平的序列多样性。
仅利用序列数据进行训练
PLAID 模型的一个重要特点是它仅需要序列数据即可训练!生成模型学习由其训练数据定义的分布,而由于获取序列比实验测量结构便宜得多,序列数据库远大于结构数据库。
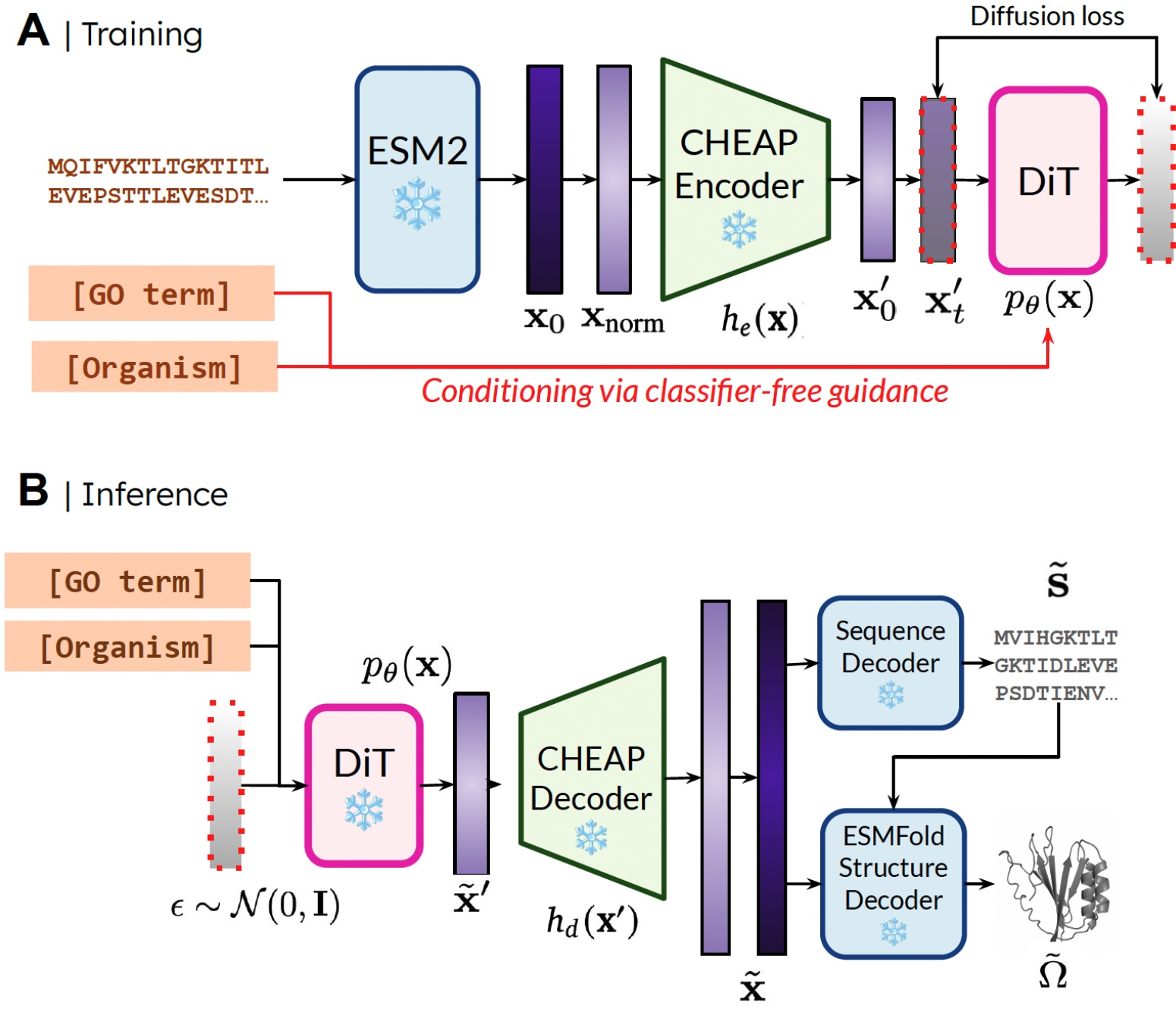
我们的方法。 在训练过程中,仅需序列即可获得嵌入;在推理过程中,我们可以从采样的嵌入中解码序列和结构。❄️ 表示冻结的权重。
通过学习蛋白质折叠模型的潜在空间上的扩散模型,我们在推理阶段可以利用预训练蛋白质折叠模型的冻结权重来解码结构。这里我们使用了 ESMFold,它是 AlphaFold2 的继任者,通过蛋白质语言模型取代了检索步骤。
压缩蛋白质折叠模型的潜在空间
直接应用该方法的一个小难点是,ESMFold(以及许多基于 Transformer 的模型)的潜在空间需要大量的正则化,且维度极高。为了解决这个问题,我们提出了 CHEAP(蛋白质的压缩沙漏嵌入适配),通过学习蛋白质序列和结构的联合嵌入压缩模型,证明了该潜在空间具有高度可压缩性。
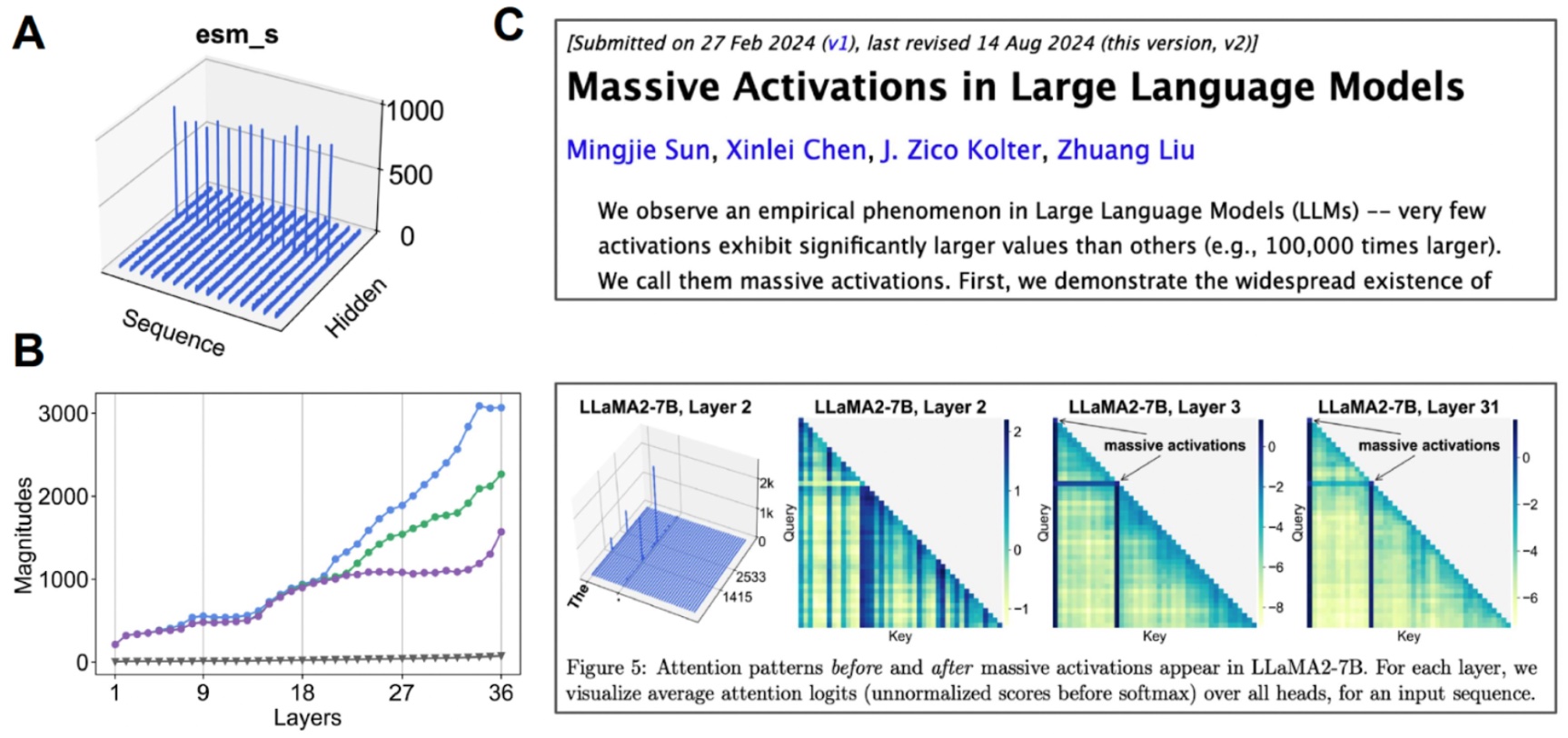
探索潜在空间。 通过机械解释性分析,我们发现即使在高层中,某些激活也表现出显著特征,这为全原子蛋白质生成模型的构建提供了基础。
展望未来
虽然我们在此项工作中关注的是蛋白质序列和结构的生成,但该方法可以推广到任何存在从“更丰富模态”到“较稀缺模态”预测器的场景中。随着蛋白质序列到结构预测器不断应对更复杂的系统,我们期待在更复杂的生物系统上应用该多模态生成方法。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区