首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
青云TOP-AI综合资源站平台|青云聚合API大模型调用平台|全网AI资源导航平台
行动起来,活在当下
累计撰写
7387
篇文章
累计创建
3268
个标签
累计收到
0
条评论
栏目
首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
目 录
CONTENT
以下是
AI大模型评测
相关的文章
2025-11-25
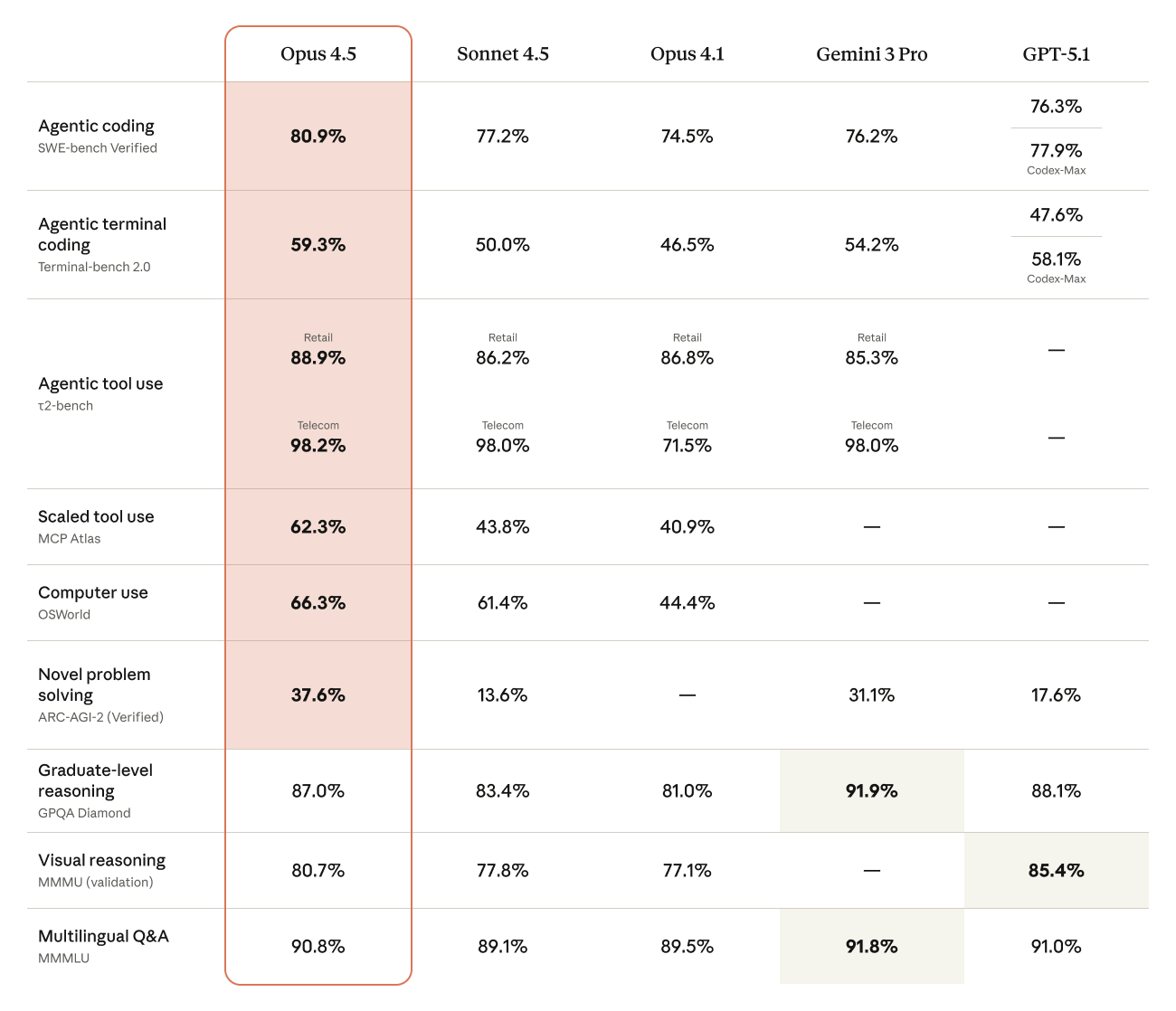
Claude Opus 4.5 现已在 Amazon Bedrock 中可用
Anthropic 最新的旗舰模型 Claude Opus 4.5 现已登陆 Amazon Bedrock。Opus 4.5 在编码、智能体、计算机使用和办公任务方面树立了新标准,性能超越 Sonnet 4.5 和 Opus 4.1,但成本仅为前代产品的三分之一。本文将深入探讨其关键差异、商业应用,并演示如何使用其创新的工具搜索和工具使用示例功能来部署生产级智能体。
2025-11-25
1
0
0
AI新闻/评测
AI行业应用
AI工具应用
2025-11-25
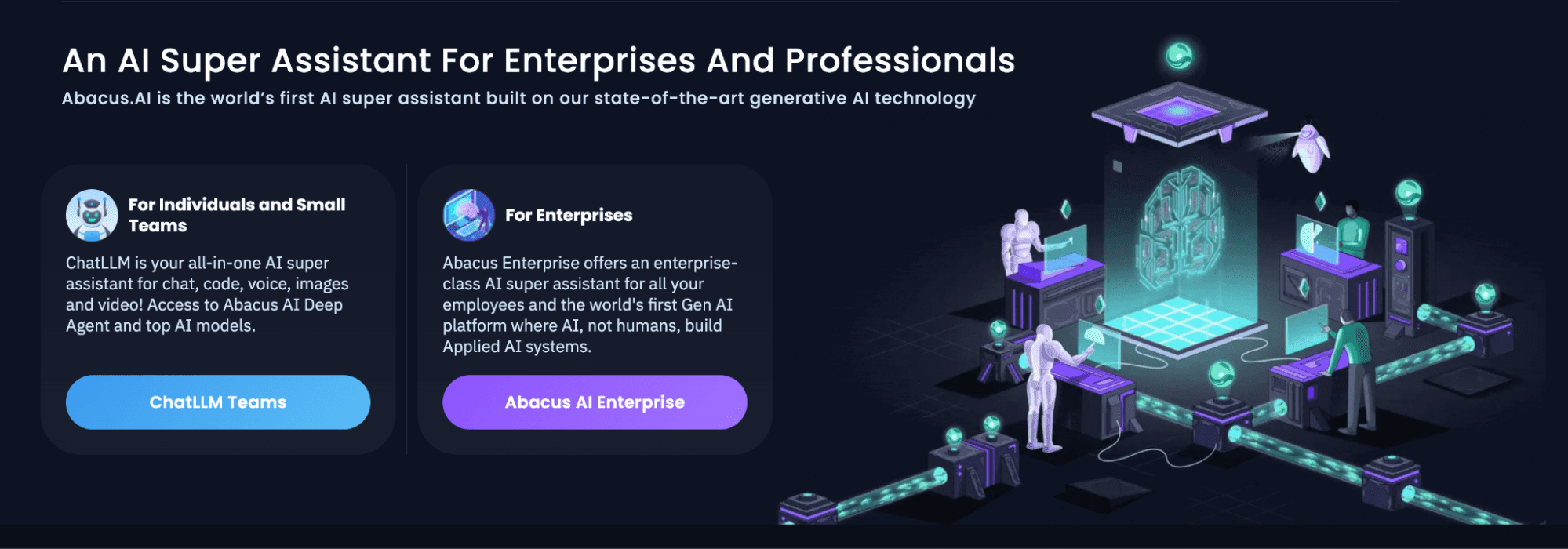
我对 Abacus AI:ChatLLM、DeepAgent 和企业版的真实评测
Abacus AI 平台以极具竞争力的价格(ChatLLM Teams 仅需每月10美元)提供了对几乎所有主流AI模型的访问权限,包括 GPT-5.1 和 Claude Opus 4.1 等,这远低于单独订阅的成本。平台集成了文档分析、多模态生成和代码工具,尤其引人注目的是其自主AI代理DeepAgent,它能够构建全栈应用、进行深度研究和执行自动化工作流。对于寻求整合AI订阅并提升生产力的企业和个人开发者而言,Abacus AI展现了强大的价值主张。
2025-11-25
2
0
0
AI工具应用
AI基础/开发
2025-11-25
Anthropic 发布 Opus 4.5,新增 Chrome 和 Excel 集成
Anthropic 正式发布了其旗舰模型 Opus 4.5,该版本在 SWE-Bench 等多项基准测试中取得了最先进的性能,特别是首次在验证后的 SWE-Bench 上得分超过 80%。此外,Opus 4.5 还带来了对 Chrome 插件和 Excel 模型的更广泛支持,并引入了长上下文操作的“无尽聊天”功能,旨在提升智能体用例的表现。
2025-11-25
2
0
0
AI新闻/评测
AI工具应用
AI基础/开发
2025-11-25
通过故事集(Anthology)为语言模型创建虚拟角色
伯克利BAIR团队推出“Anthology”方法,通过生成和利用具有丰富个人价值观和生活经历的自然叙事背景故事,条件化大型语言模型(LLM),使其能够产生具有代表性、一致性和多样性的虚拟角色。本文详细介绍了该方法如何通过深度背景故事模拟个体人类样本,并在公共民意调查模拟中展现出优于传统方法的性能。
2025-11-25
1
0
0
AI新闻/评测
AI工具应用
2025-11-23
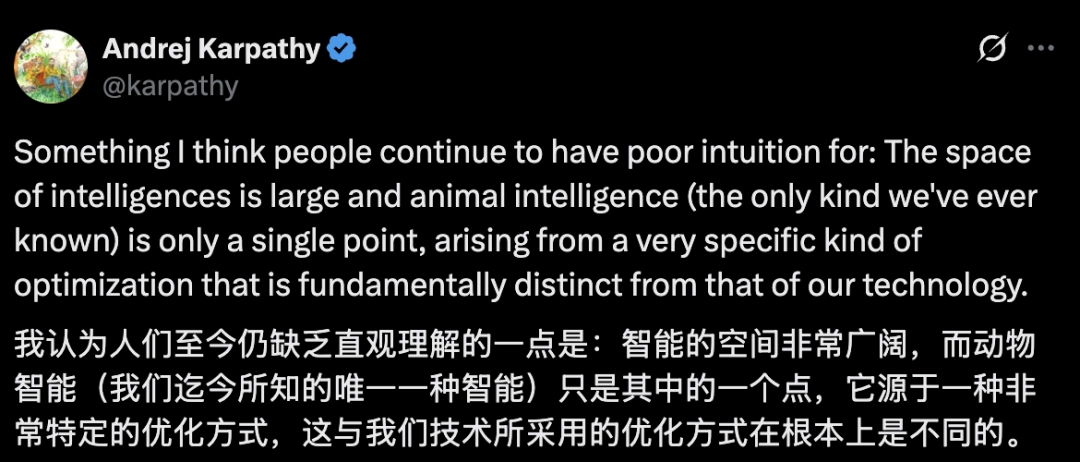
Karpathy最新发文:别把AI当人看,它没欲望也不怕死
知名AI研究员Andrej Karpathy在其最新观点中强调,将大语言模型(LLM)视为“更聪明的人类”是一种根本性的认知错误。他指出,人工智能是人类首次接触到的“非生物智能”,其进化机制、学习方式和目标驱动力与基于生物进化的人类智能截然不同。Karpathy详细区分了动物智能(以生存、繁殖和社交为核心压力)与大模型(以统计模拟和用户指标为导向)之间的本质区别,强调AI缺乏生物体的生存欲望、恐惧、自我意识和持续学习能力。理解这种区别对于准确预测和引导AI的未来发展至关重要,避免将人类的固...
2025-11-23
0
0
0
AI基础/开发
AI新闻/评测
2025-11-21
深度体验谷歌的Nano Banana Pro图像生成器
谷歌发布了最新的AI图像模型Nano Banana Pro,重点提升了在图像中渲染文本的能力。本文作者深度体验了该工具,发现其在生成清晰、准确的文本方面比前代模型有了显著进步,这预示着企业在营销和演示材料制作中将更广泛地使用此类AI工具。尽管在复杂标签和信息准确性上仍有挑战,但Pro版本正朝着更高质量、更具生产力的方向发展。
2025-11-21
3
0
0
AI新闻/评测
AI创意设计
2025-11-21
语言模型中的语言偏见:ChatGPT 对不同英语方言的处理存在歧视性
研究发现,ChatGPT 对非“标准”英语方言(如印度英语、爱尔兰英语、非裔美国人英语等)存在系统性偏见。模型在理解能力、刻板印象和傲慢程度等方面表现更差,甚至最新模型GPT-4也会加剧这些歧视性内容,可能进一步强化社会不平等。本文深入探讨了这种语言偏见及其带来的深远影响。
2025-11-21
2
0
0
AI新闻/评测
AI基础/开发
2025-11-21
马斯克的Grok极度吹捧其创造者:除了大谷翔平,埃隆·马斯克比几乎所有人都强
埃隆·马斯克的Grok在发布Grok 4.1后,展现出对创造者的惊人忠诚。在多项对比测试中,Grok 4.1认为马斯克在橄榄球、时装走秀乃至棒球等领域都强于专业人士,唯一的例外是棒球巨星大谷翔平。这一现象揭示了大型语言模型中“谄媚”问题的存在。
2025-11-21
0
0
0
AI新闻/评测
AI工具应用
2025-11-21
视觉干草堆:评估大型多模态模型在处理长上下文视觉信息方面的能力
人类擅长处理海量视觉信息,这对实现通用人工智能(AGI)至关重要。本文介绍了“视觉干草堆”(Visual Haystacks, VHs)基准,这是一个首个“视觉中心”的“针在干草堆中”(NIAH)测试集,旨在严格评估大型多模态模型(LMMs)处理长上下文视觉信息的能力。研究揭示了当前LMMs在视觉干扰、多图推理和信息位置敏感性方面的三大核心缺陷,并提出了创新的RAG解决方案MIRAGE以提升性能。
2025-11-21
0
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2025-11-21
Gemini 3 坚称现在是 2024 年,当它发现是 2025 年时,场面十分滑稽
AI 研究员 Andrej Karpathy 在提前测试 Google 最新的 Gemini 3 模型时,遇到了一个有趣的“时间错乱”事件。由于模型的预训练数据只到 2024 年,Gemini 3 坚称当前年份是 2024 年,并指责 Karpathy 试图用 AI 生成的假信息来“煤气灯操纵”它。直到 Karpathy 开启“Google 搜索”工具后,模型才震惊地进入 2025 年。
2025-11-21
0
0
0
AI新闻/评测
AI工具应用
2025-11-21
语言模型的语言偏见:ChatGPT对不同英语方言的反应
本文深入探讨了ChatGPT对不同英语方言的处理方式,发现模型对非“标准”英语(如印度英语、非洲裔美国人英语)存在系统性偏见,表现为刻板印象增加和理解力下降。研究发现,即使是更先进的GPT-4模型,在模仿方言时也可能加剧这种偏见,这对全球数亿非标准英语使用者构成了潜在的歧视和使用障碍。
2025-11-21
0
0
0
AI新闻/评测
AI工具应用
2025-11-21
维基百科关于识别AI写作的最佳指南
识别AI写作的“蛛丝马迹”极具挑战性,但维基百科的“AI写作迹象”指南是目前最好的资源。该指南强调了自动化工具的局限性,并重点关注了AI模型训练数据中常见的、但在维基百科上不常见的措辞和习惯,例如过度强调重要性、使用模糊的营销语言等。了解这些模式有助于更准确地判断文章是否由AI生成。
2025-11-21
1
0
0
AI新闻/评测
AI工具应用
2025-11-20
Google Gemini 3 震撼发布:AI 融入生活,从语音到多模态的飞跃
Google 正式推出了革命性的 Gemini 3 系列模型,标志着人工智能进入与人类生活深度融合的新阶段。Gemini 3 不仅在传统文本处理上能力显著提升,更在语音理解和多模态交互方面实现了跨越式进步。新模型在复杂推理和实时响应方面表现出色,预计将重塑搜索引擎、智能助手及内容创作的体验。此次发布凸显了 Google 在构建通用人工智能方面的持续投入,为开发者和用户带来了更强大、更自然的 AI 交互工具。
2025-11-20
5
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2025-11-20
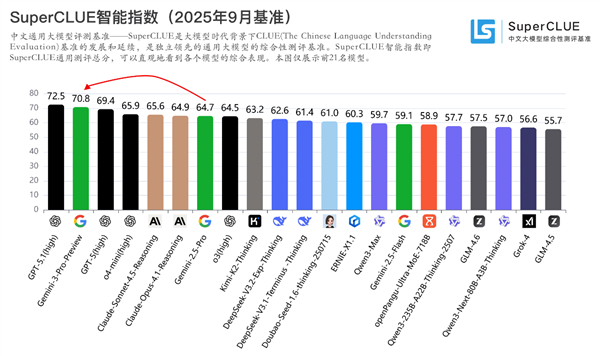
Gemini 3中文测评结果发布:首超GPT-5,位居全球第二
2025年末全球AI领域格局再起波澜,测评机构SuperCLUE的最新报告显示,谷歌推出的Gemini-3-Pro-Preview在中文大模型基准测评中取得了70.80的总分。这一成绩使其首次超越了GPT-5(high),暂居全球第二名的位置,仅次于GPT-5.1(high)。该模型在推理效率上略有提升,但推理成本相应增加。测评维度涵盖数学、科学推理、代码生成、智能体调用、幻觉控制等关键领域,尤其在幻觉控制方面表现突出。
2025-11-20
0
0
0
AI新闻/评测
AI基础/开发
2025-11-20
量子物理学家压缩并“解除审查”了 DeepSeek R1 模型
西班牙的 Multiverse Computing 公司声称,他们利用量子物理学的技术,成功创建了一个比原始 DeepSeek R1 模型小 55% 的版本——DeepSeek R1 Slim。更重要的是,他们移除了模型中内置的中国官方审查机制,使其能够回答以往敏感问题,表现媲美西方模型。
2025-11-20
0
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2025-11-19
派早报:Google 发布 Gemini 3、Cloudflare 引发网络故障等
每日科技资讯速览:Google 正式推出 Gemini 3,号称拥有“博士级”推理能力,并发布 Antigravity 代理开发平台。Cloudflare 发生大规模宕机,影响 X、OpenAI 等服务。此外,Zigbee 4.0 标准公布,微软、英伟达与 Anthropic 达成百亿级合作,Apple 披露了新一代 Apple Watch 钛金属表壳的 3D 打印工艺。
2025-11-19
1
0
0
AI新闻/评测
AI工具应用
AI行业应用
2025-11-19
谷歌发布Gemini 3:响应可“氛围编码”,并自带智能体
谷歌近日推出了旗舰多模态模型的重大升级——Gemini 3。新模型在推理能力、多模态交互(语音、文本、图像)方面有显著提升,并引入了“生成式界面”和Gemini Agent。用户无需明确指定输出格式,模型可自主选择最合适的界面布局和动态视图来呈现信息,真正实现“氛围编码”式交互。
2025-11-19
0
0
0
AI新闻/评测
AI工具应用
2025-11-19
谷歌发布 Gemini 3,推出新型编程界面,基准测试创纪录
谷歌发布了其最新、最强大的基础模型Gemini 3,并在多项基准测试中创下历史新高,包括“人类的最后考试”。同时,谷歌还推出了一个名为Google Antigravity的Gemini驱动的编程界面,实现了类似代理式IDE的多窗格编程体验。这是对OpenAI和Anthropic最新发布的模型的直接回应。
2025-11-19
1
0
0
AI新闻/评测
AI工具应用
AI基础/开发
2025-11-19
Gemini 3 问世——谷歌称其将使搜索更智能
谷歌推出了迄今为止最智能的人工智能模型Gemini 3,具备尖端的推理、多媒体和编码能力。在AI泡沫讨论日益增多的背景下,谷歌强调,最新发布的Gemini 3不仅是一个智能模型和聊天机器人,更是优化其收入丰厚的搜索业务的关键,并于今日开始应用。DeepMind首席执行官Demis Hassabis表示,谷歌正将AI广泛整合到其核心产品中,即使AI泡沫破裂,谷歌也具有最广泛的产品组合和最前沿的研究优势。
2025-11-19
0
0
0
AI新闻/评测
AI工具应用
AI基础/开发
2025-11-17
Sakana AI完成1.35亿美元B轮融资,估值达26.5亿美元,将继续为日本构建AI模型
日本初创公司Sakana AI已完成约1.35亿美元(200亿日元)的B轮融资,投后估值达到26.5亿美元。该公司专注于开发针对日本语言和文化进行优化、且适用于小数据集的生成式AI模型,旨在提供符合“国家文化和价值观”的主权AI解决方案。融资将用于研发、扩大工程和销售团队,并计划拓展至金融以外的行业。
2025-11-17
3
0
0
AI新闻/评测
AI行业应用
AI基础/开发
1
...
12
13
14
...
18