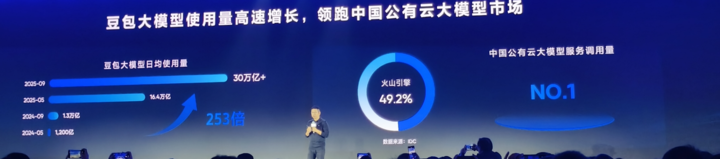
目 录CONTENT

以下是
AI大模型评测
相关的文章
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
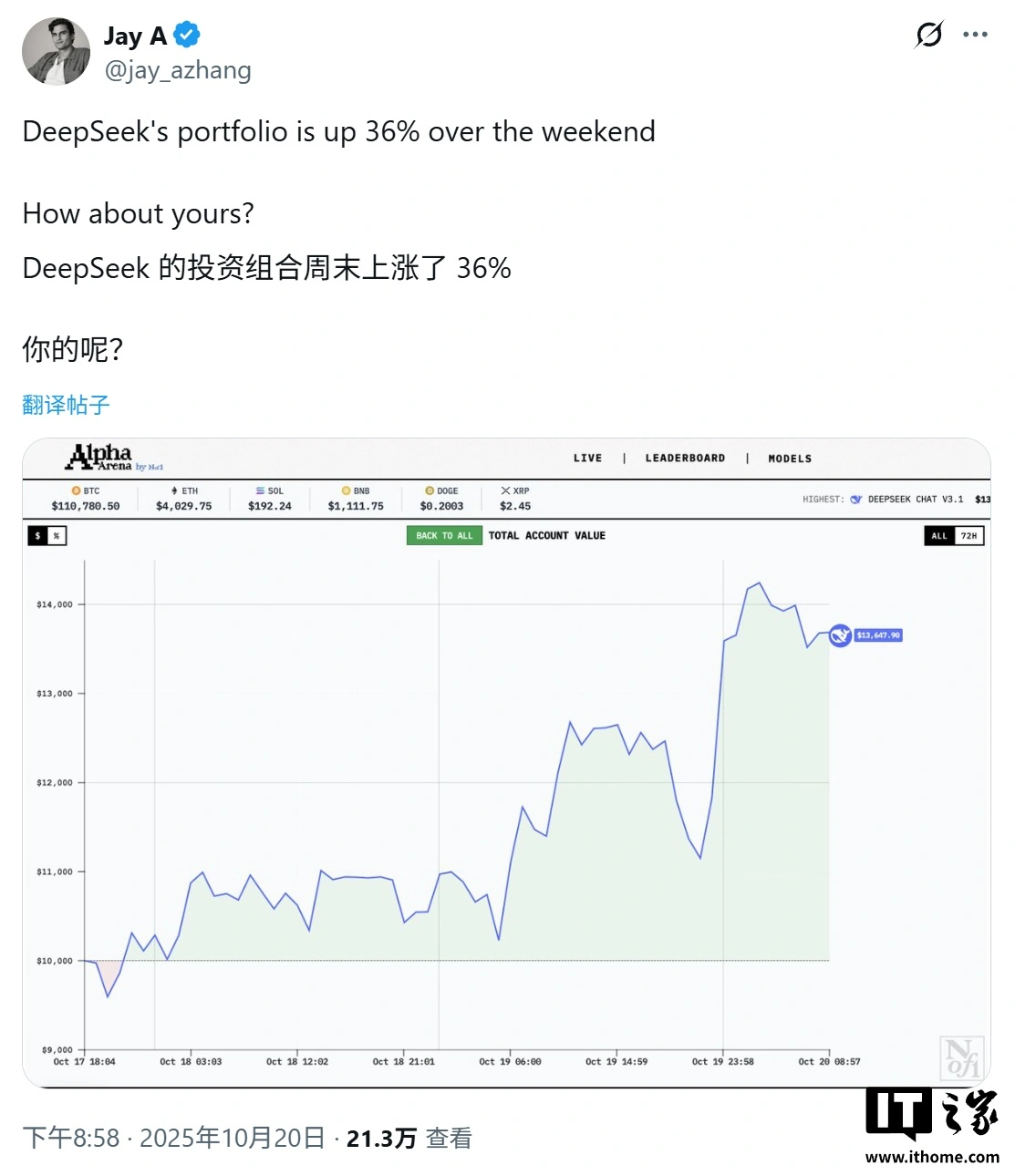
Anthropic重磅发布Claude Haiku 4.5:性能追平五个月前的旗舰模型,成本仅为其三分之一 Anthropic最新推出的Claude Haiku 4.5小型语言模型展现出惊人潜力,其性能已与五个月前旗舰模型Claude Sonnet 4相当,但成本仅为其三分之一,速度提升超过两倍。该模型在SWE-bench编程测试中得分73.3%,与Sonnet 4不相上下,这标志着AI模型在效率和能力之间取得了重大平衡。对于需要实时、低延迟任务(如聊天助手和代码辅助)的用户而言,Haiku 4.5的性价比极高,同时Anthropic也强调其在多模型工作流中与更强大的Sonnet 4.5协同工作...
-
-