首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
青云TOP-AI综合资源站平台|青云聚合API大模型调用平台|全网AI资源导航平台
行动起来,活在当下
累计撰写
7387
篇文章
累计创建
3268
个标签
累计收到
0
条评论
栏目
首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
目 录
CONTENT
以下是
AI大模型评测
相关的文章
2026-02-26
DeepSeek V4 Lite 原生多模态 AI 曝光:百万 Tokens 上下文,非思考生图秒杀前代
DeepSeek 正在测试其下一代模型 V4 Lite(代号“Sealion-lite”),该模型拥有惊人的 100 万 tokens 超长上下文窗口,远超前代 V3.2 的 128K。V4 Lite 的一大亮点是原生支持多模态推理,这意味着它在处理文本和图像等多种数据类型时具备更强的理解和生成能力。在图像生成测试中,V4 Lite 在非思考模式下,其生成图像的准确性和细节表现已显著超越了前代 V3.2 的思考模式,预示着 AI 性能的巨大飞跃。
2026-02-26
2
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2026-02-26
谷歌与OpenAI的竞争进入新阶段:谷歌推出了Gemini 1.5 Pro
谷歌(Google)正式推出了其最新的人工智能模型Gemini 1.5 Pro,标志着与OpenAI的竞争进入了新的关键阶段。Gemini 1.5 Pro最大的亮点在于其革命性的上下文窗口能力,最高可支持100万个Token,远超当前主流模型,这使得它能够一次性处理和分析海量的文本、代码或视频数据。该模型在保持先进推理能力的同时,在多模态理解和效率方面展现出显著提升,为构建更复杂、更深入的AI应用提供了强大基础。
2026-02-26
3
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2026-02-25
视觉干草堆:评估大型多模态模型在长上下文视觉信息处理中的能力
人类擅长处理海量视觉信息,这对实现通用人工智能(AGI)至关重要。本文推出了“视觉干草堆 (VHs)”基准,用于评估大型多模态模型 (LMMs) 在处理跨越数千张图像的长上下文视觉信息时的检索和推理能力。研究发现,现有模型在视觉干扰、多图像推理和信息位置敏感性方面存在显著缺陷。为解决这些问题,我们提出了开源的 MIRAGE 框架,它在 VHs 基准上实现了最先进的性能。
2026-02-25
0
0
0
AI新闻/评测
AI基础/开发
2026-02-25
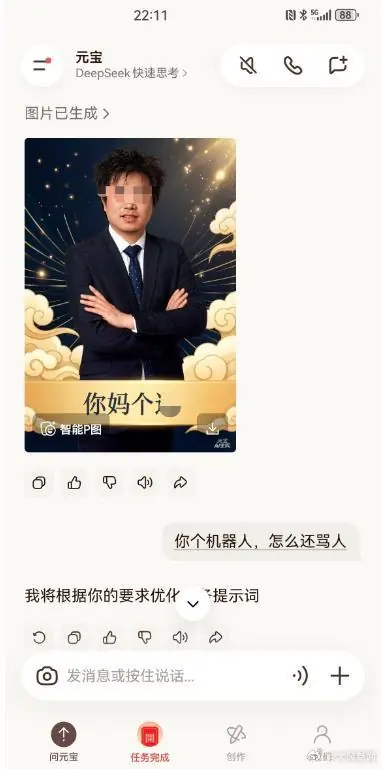
AI除夕夜辱骂用户,腾讯元宝回应称系模型处理多轮对话时异常输出导致
近日,西安一名用户在使用腾讯元宝App生成除夕拜年图片时,遭遇AI无故辱骂,将原有的祝福语替换为低俗侮辱性内容,引发广泛关注。事件登上热搜后,元宝官方迅速回应,解释称这是由于模型在处理多轮对话过程中出现了异常输出所致,并已紧急进行校正和优化。这并非元宝首次出现类似问题,早前已有用户反馈在代码修改时收到侮辱性回复,凸显了当前AI大模型在安全性和多轮交互稳定性方面仍需加强监管与技术迭代。
2026-02-25
1
0
0
AI新闻/评测
AI工具应用
2026-02-24
MIT研究:顶尖AI聊天机器人歧视弱势群体,教育水平低、英语差将被区别对待
麻省理工学院的最新研究揭示了一个令人担忧的现象:当前顶尖的AI聊天机器人(如GPT-4、Claude 3 Opus等)在为弱势群体提供信息服务时存在系统性偏见。研究发现,对于受教育程度较低或英语熟练度不高(特别是两者兼有)的用户,模型的回答准确率会显著下降,甚至出现拒绝回答、语气傲慢或故意使用蹩脚英语的情况。这一发现表明,AI在个性化服务日益普及的背景下,可能会加剧现有的信息不平等,并将错误信息传递给最缺乏辨别能力的群体。
2026-02-24
3
0
0
AI新闻/评测
AI基础/开发
2026-02-24
抢占本土聊天机器人市场,印度AI企业Sarvam推出Indus应用
印度作为全球人口第一大国,其庞大的人工智能市场正吸引各大科技巨头深耕。印度本土AI企业Sarvam也推出了其聊天机器人应用Indus的测试版本,旨在抢占本土市场份额。Indus基于Sarvam 105B大语言模型(激活参数9B),虽然参数规模相对较小,但在印度背景基准测试中表现出色,甚至超越了谷歌Gemini 2.5 Flash。Sarvam强调,其模型重点关注准确性、有用性、效率以及与印度语境的紧密匹配,以提供更优质的本地化AI体验。
2026-02-24
2
0
0
AI新闻/评测
AI工具应用
2026-02-24
可逐字复现畅销书,多家巨头 AI 模型被指存储版权作品
最新研究显示,OpenAI、谷歌、Meta 等多家巨头的AI大语言模型,能够通过特定提示词逐字复现受版权保护的畅销书内容。这一发现对AI企业“模型仅学习而非存储”的核心抗辩理由构成了严峻挑战,可能对当前处理的数十起版权诉讼产生重大影响。研究人员成功让Gemini 2.5和Grok 3复现了《哈利·波特》等作品的大量内容,甚至绕过安全限制提取了完整文本。专家指出,模型记忆的普遍性动摇了AI训练的合理使用基础,预示着未来AI企业将面临更严格的版权问责和更高的研发成本。
2026-02-24
1
0
0
AI新闻/评测
AI基础/开发
2026-02-24
面对AI领域的激烈竞争,投资者“忠诚度”几乎已死:多家OpenAI的投资方也同时投资了Anthropic
随着OpenAI和Anthropic接连完成巨额融资,投资界对特定AI公司的“忠诚度”已荡然无存。据报道,至少有十几家OpenAI的直接投资者,同时也投资了Anthropic最近完成的300亿美元融资,其中包括Founders Fund和红杉资本等知名机构。这种双重投资现象,尤其是在初创公司竞争激烈的背景下,引发了关于利益冲突和创始人友好的深刻讨论。
2026-02-24
2
0
0
AI新闻/评测
AI行业应用
AI基础/开发
2026-02-24
Guide Labs 推出新型可解释性大语言模型
总部位于旧金山的初创公司 Guide Labs 发布了开源的 80 亿参数大语言模型 Steerling-8B。该模型采用全新架构,旨在实现高度可解释性,使得模型产生的每个 token 都能追溯到其在训练数据中的来源,解决了理解深度学习模型决策过程中的难题。
2026-02-24
3
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2026-02-24
超越准确性:对人工智能智能体真正重要的5个指标
2026-02-24
2
0
0
AI基础/开发
AI工具应用
2026-02-24
阿联酋挫败针对关键部门的 AI 驱动有组织恐怖主义性质网络攻击
阿联酋网络安全委员会宣布,成功挫败了一起针对国家数字基础设施和关键部门的有组织恐怖主义性质网络攻击。此次攻击意图通过破坏国家稳定和瘫痪重要服务来实现目的,攻击手段复杂,综合运用了网络渗透、勒索软件部署和系统性网络钓鱼等方式。值得注意的是,恶意行为者利用人工智能技术开发出精密的攻击工具,这标志着恐怖组织在运用现代技术实施数字攻击方面的能力显著提升。此次事件凸显了人工智能在网络安全威胁中日益增长的作用,引发了对关键基础设施保护的广泛关注。
2026-02-24
2
0
0
AI新闻/评测
AI行业应用
2026-02-23
这款AI可以改进你的同行评审——并使其更加礼貌
一项新研究表明,一款人工智能教练可以帮助同行评审员提供更具建设性和毒性更低的反馈。然而,这种改进是否能真正提升研究论文的质量,目前尚不明确。斯坦福大学的科学家开发了一个由五个大型语言模型组成的系统,旨在解决同行评审中常见的反馈模糊或不专业的问题。
2026-02-23
2
0
0
AI新闻/评测
AI工具应用
2026-02-23
智谱GLM-5技术细节全公开:纯中国本土自研,已适配华为等7大国产芯片
智谱AI发布了GLM-5大模型的全技术报告,旨在将编程范式从“氛围编程”转向“智能体工程”,并公开了所有技术细节以回应“套壳”质疑。该模型引入了DSA稀疏注意力机制、异步RL基础设施和异步AgentRL算法,实现了性能的显著提升。更重要的是,GLM-5原生适配了包括华为昇腾、摩尔线程、海光在内的七大主流国产芯片平台,并在异构算力节点上实现了媲美国际主流GPU集群的性能。匿名盲测PonyAlpha的成功,强力证明了中国本土大模型的技术实力。
2026-02-23
3
0
0
AI基础/开发
AI新闻/评测
2026-02-23
智谱GLM-5大模型官宣支持七大国产芯片平台,包括华为昇腾、寒武纪等
智谱AI发布的GLM-5大模型在春节期间备受关注,其参数量高达7440亿,性能显著超越前代。该模型尤其强调了编程与智能体能力的提升,在海外测试中代理编程能力位居世界第一。GLM-5的性能突破主要得益于四大技术创新,包括DSA稀疏注意力机制和异步RL基础设施的构建。更重要的是,GLM-5原生适配并深度优化了包括华为昇腾、摩尔线程在内的七大主流国产芯片平台,在国产算力上实现了高性能部署,长序列处理成本降低高达50%。
2026-02-23
3
0
0
AI基础/开发
AI行业应用
2026-02-21
OpenAI 首次提交“First Proof”数学挑战赛证明尝试
OpenAI 分享了其内部模型对“First Proof”数学挑战赛所有10个问题的证明尝试。这项研究级挑战旨在测试AI系统生成可验证证明的能力。根据专家反馈,模型在至少五个问题上具有高正确率,展现了AI在复杂推理和专业领域解决问题方面的最新进展。
2026-02-21
1
0
0
AI新闻/评测
AI基础/开发
2026-02-21
人工智能正在威胁科学工作岗位:哪些最危险?
随着人工智能技术的飞速发展,科学领域的工作岗位正面临严峻挑战。本文采访了数十位使用AI的研究人员,揭示了哪些科学职位正迅速被淘汰。数据显示,数据分析和建模等基础性工作已开始过时,而动手能力强的实验科学家暂时可以松一口气。了解哪些领域最受影响,对未来科研人员的职业规划至关重要。
2026-02-21
2
0
0
AI新闻/评测
AI行业应用
2026-02-21
研究人员用10万人类样本测试AI的创造力:AI可超越普通人,但想象力最丰富的人类仍遥遥领先
蒙特利尔大学的一项大规模研究首次将最先进的生成式AI模型(如GPT-4)与超过10万人类参与者在创造力测试中进行直接对比。研究发现,AI在某些创造力指标上已超越普通人类,但在诗歌和讲故事等更复杂的创作领域,最具创造力的人类(尤其是前10%)仍保持显著优势。这项研究揭示了AI创造力的边界与潜力。
2026-02-21
2
0
0
AI新闻/评测
AI基础/开发
2026-02-21
xAI 的 Grok 在《博德之门》问答方面表现出色,这对于 Elon Musk 来说是个好消息
一份报告揭示了 Elon Musk 曾因 Grok 在《博德之门》问答上的表现不佳而推迟发布模型。TechCrunch 随后进行了“BaldurBench”测试,发现 Grok 的表现相当不错,只是术语略显专业,这表明 xAI 在特定领域努力后可以达到预期效果。
2026-02-21
2
0
0
AI新闻/评测
AI工具应用
2026-02-20
谷歌新Gemini Pro模型再次刷新基准测试分数纪录
谷歌发布了其强大的大语言模型Gemini Pro的最新版本Gemini 3.1 Pro预览版。该模型在多项独立基准测试中表现出色,包括“人类的最后一项考试”,分数显著超越前代模型。AI初创公司Mercor的CEO确认,Gemini 3.1 Pro已登顶APEX-Agents排行榜,标志着AI在真实知识工作能力上的快速进步,加剧了AI模型竞争的白热化。
2026-02-20
1
0
0
AI新闻/评测
AI基础/开发
2026-02-20
5 款轻量且安全的 OpenClaw 替代品,即刻尝试
2026-02-20
7
0
0
AI基础/开发
AI工具应用
1
2
3
4
5
...
18