



📢 转载信息
原文作者:Nate Rosidi

Image by Author
# 引言
每个人都专注于解决问题,但几乎没有人测试解决方案。有时,一个完美运行的脚本可能仅因一行新数据或逻辑的微小变化而崩溃。
在本文中,我们将使用Python解决一个特斯拉的面试题,并通过遵循三个步骤,展示版本控制和单元测试如何将一个脆弱的脚本转变为可靠的解决方案。我们将从面试题开始,最终以使用GitHub Actions进行自动化测试而告终。
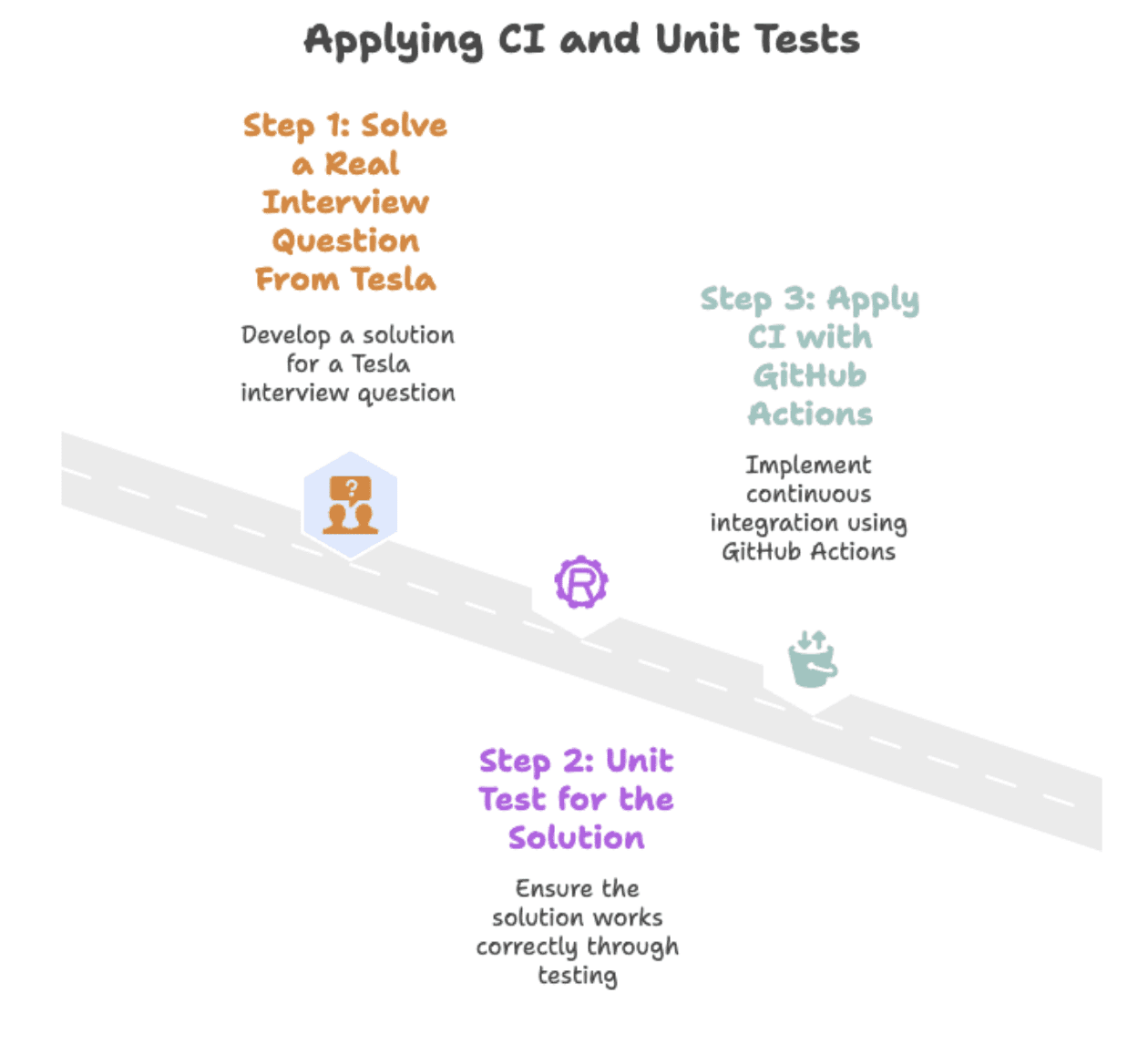
Image by Author
我们将经历以下三个步骤,使数据解决方案具备生产就绪能力。
首先,我们将解决一个真实的面试题。其次,我们将添加单元测试,以确保解决方案随着时间的推移保持可靠。最后,我们将使用GitHub Actions来自动化测试和版本控制。
# 解决一个真实的特斯拉面试题
新产品
计算公司在2020年推出的产品数量与2019年相比的净变化。输出应包括公司名称和净差异。
(净差异 = 2020年推出的产品数量 - 2019年推出的产品数量。)
在这个来自特斯拉的面试问题中,你被要求衡量两年内的产品增长情况。
任务是返回每家公司的名称以及2020年和2019年产品数量之间的差异。
// 理解数据集
让我们首先看看我们正在处理的数据集。以下是列名。
| 列名 | 数据类型 |
|---|---|
| year | int64 |
| company_name | object |
| product_name | object |
让我们预览一下数据集。
| 年份 | 公司名称 | 产品名称 |
|---|---|---|
| 2019 | Toyota | Avalon |
| 2019 | Toyota | Camry |
| 2020 | Toyota | Corolla |
| 2019 | Honda | Accord |
| 2019 | Honda | Passport |
该数据集包含三列:year、company_name和product_name。每一行代表给定年份某个公司发布的一款车型。
// 编写Python解决方案
我们将使用基本的pandas操作来按公司分组、比较并计算产品净变化。我们将编写的函数将数据拆分为2019年和2020年的子集。
接下来,它按公司名称合并它们,并计算每年的唯一产品数量。
import pandas as pd import numpy as np from datetime import datetime df_2020 = car_launches[car_launches['year'].astype(str) == '2020'] df_2019 = car_launches[car_launches['year'].astype(str) == '2019'] df = pd.merge(df_2020, df_2019, how='outer', on=[ 'company_name'], suffixes=['_2020', '_2019']).fillna(0)
最终输出将2019年的计数从2020年的计数中减去,以获得净差异。以下是完整的代码。
import pandas as pd import numpy as np from datetime import datetime df_2020 = car_launches[car_launches['year'].astype(str) == '2020'] df_2019 = car_launches[car_launches['year'].astype(str) == '2019'] df = pd.merge(df_2020, df_2019, how='outer', on=[ 'company_name'], suffixes=['_2020', '_2019']).fillna(0) df = df[df['product_name_2020'] != df['product_name_2019']] df = df.groupby(['company_name']).agg( {'product_name_2020': 'nunique', 'product_name_2019': 'nunique'}).reset_index() df['net_new_products'] = df['product_name_2020'] - df['product_name_2019'] result = df[['company_name', 'net_new_products']]
// 查看预期输出
这是预期输出。
| 公司名称 | 新产品净数 |
|---|---|
| Chevrolet | 2 |
| Ford | -1 |
| Honda | -3 |
| Jeep | 1 |
| Toyota | -1 |
# 使用单元测试使解决方案可靠
解决一次数据问题并不意味着它会一直有效。新的一行或逻辑的小调整可能会静默地破坏你的脚本。例如,想象一下你不小心在代码中重命名了一个列,将此行更改为:
df['net_new_products'] = df['product_name_2020'] - df['product_name_2019']
改为这样:
df['new_products'] = df['product_name_2020'] - df['product_name_2019']
逻辑仍然运行,但你的输出(和测试)会突然失败,因为预期的列名不再匹配。单元测试可以解决这个问题。它们会检查相同的输入是否每次都给出相同的输出。如果出现问题,测试将失败并确切显示位置。我们将分三步完成此操作,从将面试问题的解决方案转换为函数到编写检查输出是否符合预期的测试。
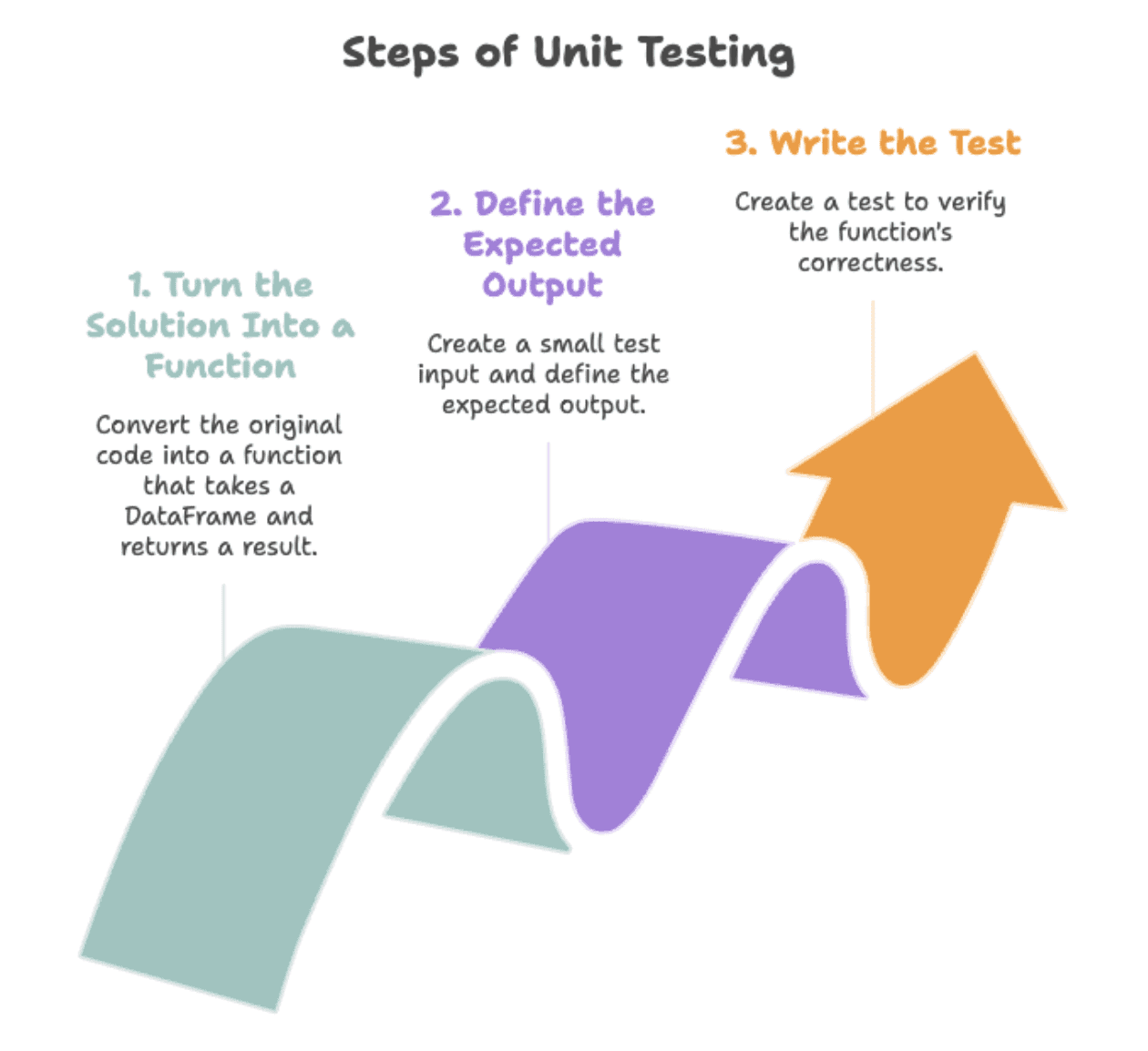
Image by Author
// 将脚本转换为可重用函数
在编写测试之前,我们需要使解决方案可重用且易于测试。将其转换为函数可以让我们用不同的数据集运行它并自动验证输出,而无需每次都重写相同的代码。我们将原始代码更改为一个接受DataFrame并返回结果的函数。这是代码。
def calculate_net_new_products(car_launches): df_2020 = car_launches[car_launches['year'].astype(str) == '2020'] df_2019 = car_launches[car_launches['year'].astype(str) == '2019'] df = pd.merge(df_2020, df_2019, how='outer', on=[ 'company_name'], suffixes=['_2020', '_2019']).fillna(0) df = df[df['product_name_2020'] != df['product_name_2019']] df = df.groupby(['company_name']).agg({ 'product_name_2020': 'nunique', 'product_name_2019': 'nunique' }).reset_index() df['net_new_products'] = df['product_name_2020'] - df['product_name_2019'] return df[['company_name', 'net_new_products']]
// 定义测试数据和预期输出
在运行任何测试之前,我们需要知道什么是“正确”的。定义预期输出为我们提供了一个清晰的基准来对照我们函数的结果。因此,我们将构建一个小的测试输入并明确定义正确的输出应该是怎样的。
import pandas as pd # 样本测试数据 test_data = pd.DataFrame({ 'year': [2019, 2019, 2020, 2020], 'company_name': ['Toyota', 'Toyota', 'Toyota', 'Toyota'], 'product_name': ['Camry', 'Avalon', 'Corolla', 'Yaris'] }) # 预期输出 expected_output = pd.DataFrame({ 'company_name': ['Toyota'], 'net_new_products': [0] # 2 in 2020 - 2 in 2019 })
// 编写和运行单元测试
以下测试代码检查你的函数返回的结果是否与你期望的完全一致。
如果不匹配,测试将失败并告诉你原因,精确到最后一行或一列。
下面的测试使用了前一步骤中的函数(calculate_net_new_products())和我们定义的预期输出。
import unittest class TestProductDifference(unittest.TestCase): def test_net_new_products(self): result = calculate_net_new_products(test_data) result = result.sort_values('company_name').reset_index(drop=True) expected = expected_output.sort_values('company_name').reset_index(drop=True) pd.testing.assert_frame_equal(result, expected) if __name__ == '__main__': unittest.main()
# 使用持续集成自动化测试
编写测试是一个好的开始,但前提是它们确实运行了。你可以在每次更改后手动运行测试,但这无法扩展,容易忘记,而且团队成员可能有不同的设置。持续集成(CI)通过在代码更改推送到仓库时自动运行测试来解决这个问题。
GitHub Actions是一个免费的CI工具,它在每次推送时执行此操作,即使代码、数据或逻辑发生变化,也能保持解决方案的可靠性。它会在每次推送时自动运行你的测试,因此即使代码、数据或逻辑发生变化,你的解决方案也能保持可靠。以下是如何使用GitHub Actions应用CI的方法。
Image by Author
// 组织项目文件
要将CI应用于面试查询,你首先需要将解决方案推送到GitHub仓库。(要了解如何创建GitHub仓库,请阅读此处)。
然后,设置以下文件:
solution.py:来自步骤2.1的面试问题解决方案expected_output.py:定义步骤2.2中的测试输入和预期输出test_solution.py:使用步骤2.3中的unittest的单元测试requirements.txt:依赖项(例如,pandas).github/workflows/test.yml:GitHub Actions工作流文件data/car_launches.csv:解决方案使用到的输入数据集
// 理解仓库布局
仓库的组织方式使得GitHub Actions无需额外设置就能在你的GitHub仓库中找到所需的一切。这使事情保持简单、一致,并且对你和他人来说都易于使用。
my-query-solution/ ├── data/ │ └── car_launches.csv ├── solution.py ├── expected_output.py ├── test_solution.py ├── requirements.txt └── .github/ └── workflows/ └── test.yml
// 创建GitHub Actions工作流
现在你已经有了所有文件,你需要最后一个文件,即test.yml。该文件告诉GitHub Actions如何在代码更改时自动运行测试。
首先,我们命名工作流并告诉GitHub何时运行它。
name: Run Unit Tests on: push: branches: [ main ] pull_request: branches: [ main ]
这意味着每当有人在main分支上推送代码或打开拉取请求时,测试就会运行。接下来,我们创建一个定义工作流中将发生什么的作业。
jobs: test: runs-on: ubuntu-latest
该作业在GitHub的Ubuntu环境中运行,每次都能为你提供干净的设置。现在我们向该作业添加步骤。第一个步骤是检出你的仓库,以便GitHub Actions可以访问你的代码。
- name: Checkout repository uses: actions/checkout@v4
然后我们设置Python并选择我们想要使用的版本。
- name: Set up Python uses: actions/setup-python@v5 with: python-version: "3.10"
之后,我们安装requirements.txt中列出的所有依赖项。
- name: Install dependencies run: | python -m pip install --upgrade pip pip install -r requirements.txt
最后,我们运行项目中的所有单元测试。
- name: Run unit tests run: python -m unittest discover
最后一步会自动运行你的测试,如果出现任何错误,它会显示出来。以下是完整的参考文件:
name: Run Unit Tests on: push: branches: [ main ] pull_request: branches: [ main ] jobs: test: runs-on: ubuntu-latest steps: - name: Checkout repository uses: actions/checkout@v4 - name: Set up Python uses: actions/setup-python@v5 with: python-version: "3.10" - name: Install dependencies run: | python -m pip install --upgrade pip pip install -r requirements.txt - name: Run unit tests run: python -m unittest discover
// 在GitHub Actions中审查测试结果
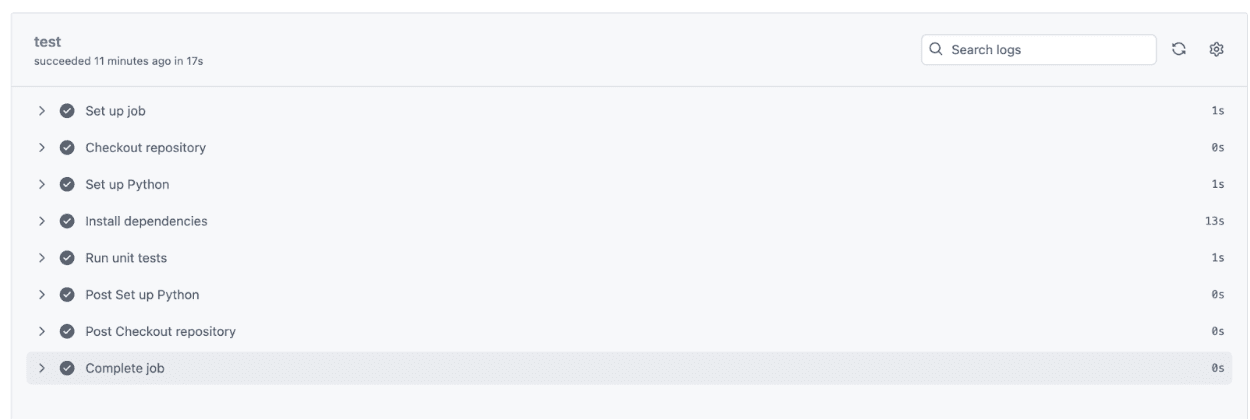
将所有文件上传到GitHub仓库后,点击Actions进入Actions标签页,如图所示。
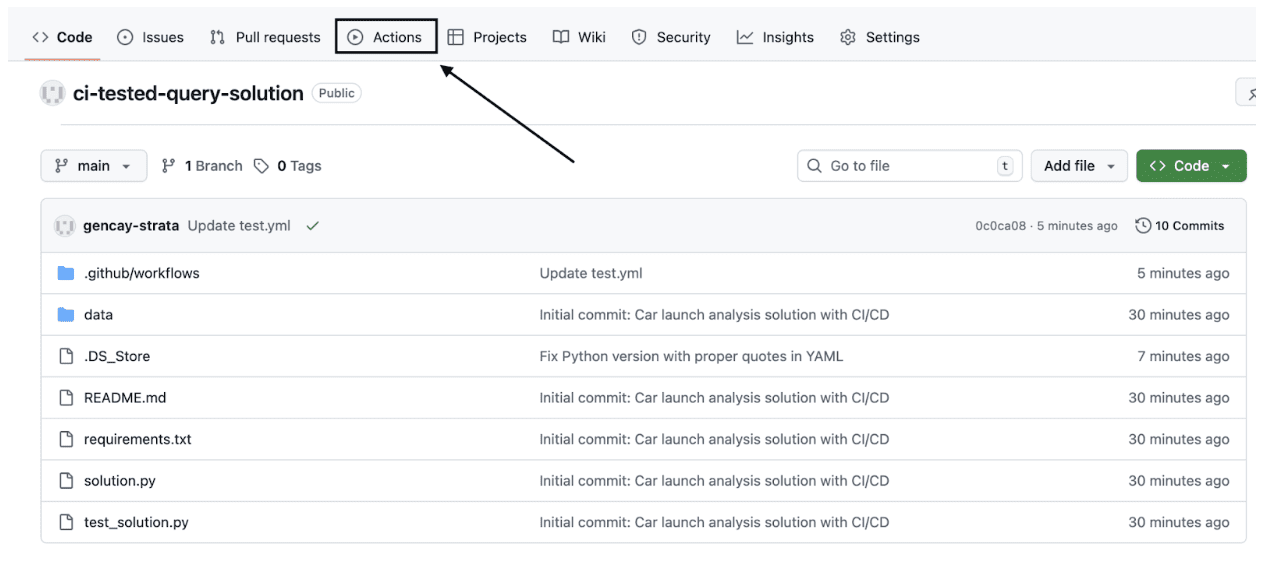
点击进入Actions后,如果一切运行成功,你会看到一个绿色的对勾,如下面的截图所示。

点击进入“Update test.yml”可以查看实际发生的情况。你会得到从设置Python到运行测试的完整细分。如果所有测试都通过了:
- 每个步骤都会有一个对勾标记。
- 这确认了所有事情都如预期般工作。
- 这意味着你的代码在每个阶段都表现符合预期,基于你定义的测试。
- 输出与你创建这些测试时设定的目标相匹配。
让我们看看:
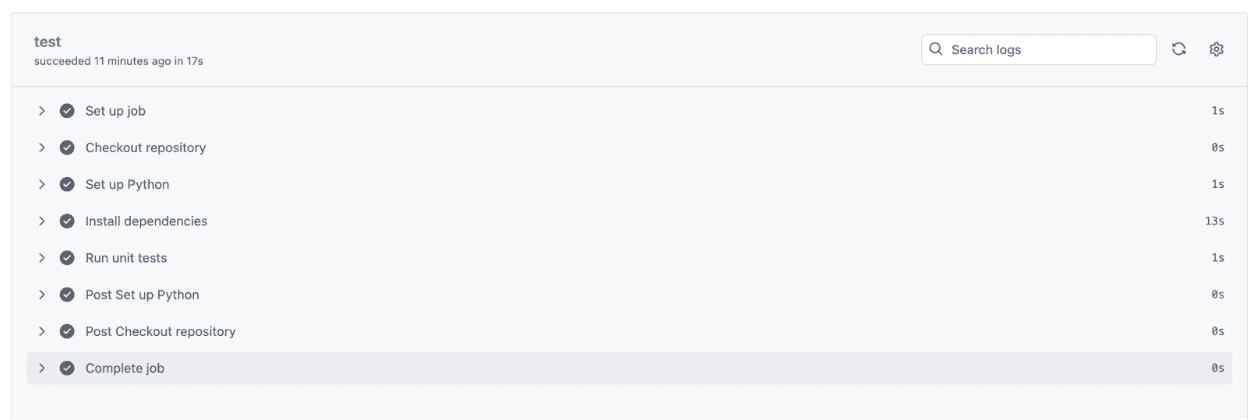
正如你所见,我们的单元测试仅用了1秒钟就完成了,整个CI过程在17秒内完成,验证了从设置到测试执行的所有内容。
// 当一个小更改破坏测试时
并非所有的更改都会通过测试。假设你在solution.py中不小心重命名了一个列,然后将更改发送到GitHub,例如:
# 原版(运行正常) df['net_new_products'] = df['product_name_2020'] - df['product_name_2019'] # 意外更改 df['new_products'] = df['product_name_2020'] - df['product_name_2019']
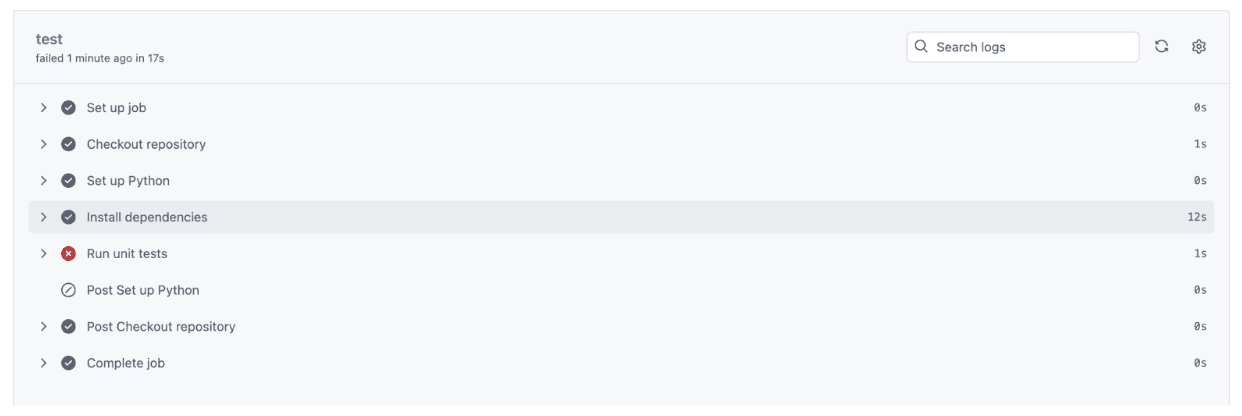
现在我们来看看Actions标签页中的测试结果。

我们有一个错误。让我们点击它查看详情。
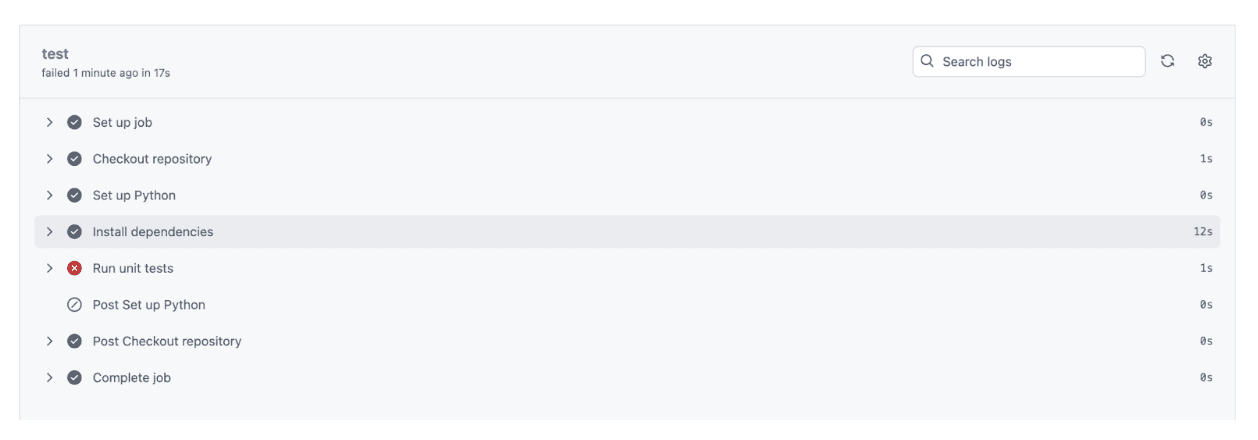
单元测试未通过,所以我们点击“Run unit tests”查看完整的错误消息。
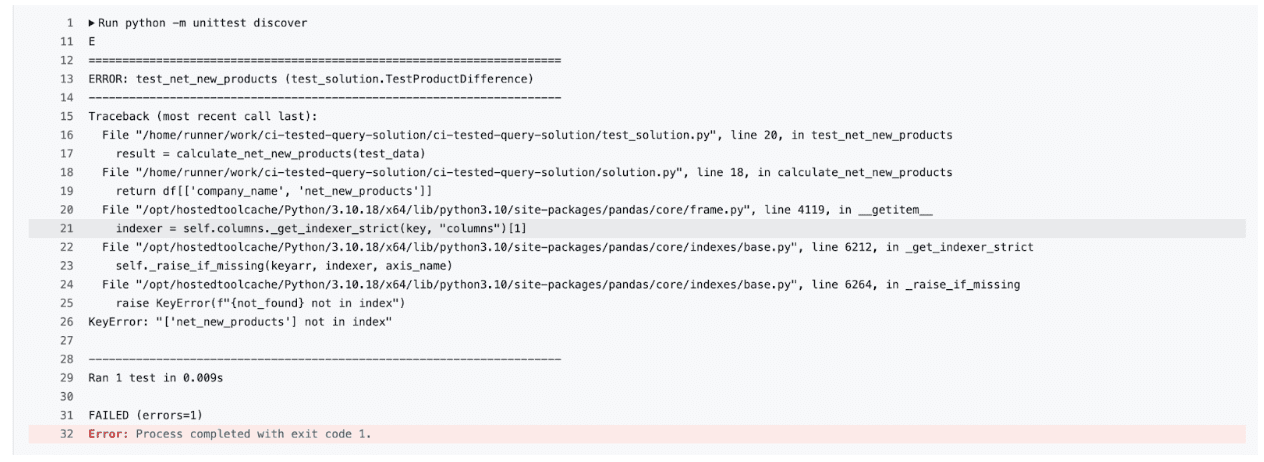
正如你所见,我们的测试发现了问题,出现了一个KeyError: 'net_new_products',因为函数中的列名不再与测试的预期相匹配。
这就是你如何对代码进行持续检查。如果你的团队成员犯了错误,测试可以充当你的安全网。
# 使用版本控制来跟踪和测试更改
版本控制可以帮助你跟踪所做的每一项更改,无论是逻辑、测试还是数据集中的更改。假设你想尝试一种新的数据分组方式。不要直接编辑主脚本,而是创建一个新分支:
git checkout -b refactor-grouping
接下来的步骤如下:
- 进行更改,提交它们,并运行测试。
- 如果所有测试都通过,意味着代码按预期工作,则合并它。
- 如果未通过,则回滚分支,不影响主代码。
这就是版本控制的力量:每一项更改都会被跟踪、可测试且可逆。
# 总结
大多数人得到正确答案后就停止了。但现实世界中的数据解决方案要求更多。它们奖励那些能够构建经得起时间考验的查询的人,而不仅仅是一次性的查询。
通过版本控制、单元测试和简单的CI设置,即使是一次性的面试问题也可以成为你作品集中可靠、可重用的部分。
Nate Rosidi是一位数据科学家和产品战略师。他也是一位兼职教授,教授分析学,并且是StrataScratch的创始人,该平台通过顶级公司的真实面试问题帮助数据科学家准备面试。Nate撰写关于职业市场最新趋势、提供面试建议、分享数据科学项目以及涵盖SQL相关的一切内容。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区