



📢 转载信息
原文作者:Tony Santiago, Adewale Akinfaderin, Sharon Li, and Sundaresh Iyer
Amazon Nova 多模态嵌入通过单一模型架构处理文本、文档、图像、视频和音频。该模型可通过 Amazon Bedrock 使用,它能将不同输入模态转换为同一向量空间中的数值嵌入,支持直接进行相似性计算,而无需考虑内容类型。我们开发这个统一模型是为了减少对独立嵌入模型的依赖,因为后者会使架构复杂化、难以维护和操作,并进一步将用例限制为一维方法。
在本文中,我们将通过一个实际的电子商务用例,探讨 Amazon Nova 多模态嵌入如何解决跨模态搜索的挑战。我们将研究传统方法的技术限制,并演示 Amazon Nova 多模态嵌入如何实现跨文本、图像和其他模态的检索。您将学习如何通过生成嵌入、处理查询和衡量性能来实现跨模态搜索系统。我们将提供可运行的代码示例,并分享如何将这些功能添加到您的应用程序中。
搜索问题
传统方法涉及基于关键字的搜索、基于文本嵌入的自然语言搜索或混合搜索,但无法有效处理视觉查询,这在用户意图和检索能力之间造成了差距。典型的搜索架构会分离视觉和文本处理,从而在过程中丢失上下文。文本查询针对产品描述执行关键字匹配或文本嵌入。图像查询(如果支持)通过多个计算机视觉管道操作,与文本内容的集成有限。这种分离使系统架构复杂化,并削弱了用户体验。多个嵌入模型需要单独的维护和优化周期,而跨模态查询无法在单个系统中原生处理。视觉和文本相似度分数存在于不同的数学空间中,使得跨内容类型的结果排序变得困难。这种分离需要复杂的映射,而这种映射并非总是可行,因此嵌入系统会保持独立,从而在过程中形成数据孤岛并限制功能。复杂的产品内容使情况更加复杂,因为产品页面结合了图像、描述、规格,有时还有视频演示。
跨模态嵌入
跨模态嵌入将文本、图像、音频和视频映射到共享的向量空间中,语义相似的内容会聚集在一起。例如,当处理文本查询 red summer dress(红色夏季连衣裙)和一张红色连衣裙的图像时,两个输入都会在嵌入空间中生成接近的向量,反映它们的语义相似性,从而实现跨模态检索。
通过使用跨模态嵌入,您可以在不同内容类型之间进行搜索,而无需为每种模态维护单独的系统,从而解决了分段多模态系统的难题——组织通常管理着多个嵌入模型,但由于不同模态的嵌入不兼容,这些模型几乎不可能有效集成。单一的模型架构有助于确保所有内容类型的嵌入生成一致,同时由于联合训练目标,相关内容(如产品图像、视频及其描述)会生成相似的嵌入。应用程序可以使用相同的 API 端点和向量维度为所有内容类型生成嵌入,从而降低系统复杂性。
用例:电子商务搜索
设想一位顾客在电视上看到一件衬衫,想找类似商品购买。他们可以用手机拍下物品,或者尝试用文字描述他们看到的内容进行搜索。传统搜索对引用元数据的文本查询处理得相当好,但当客户想使用图像进行搜索或描述物品的视觉属性时,就无法执行了。这种“电视到购物车”的购物体验展示了视觉搜索和文本搜索如何协同工作。顾客上传照片,系统将其与包含图像和描述的产品目录进行匹配。下图显示了跨模态电子商务的工作流程。
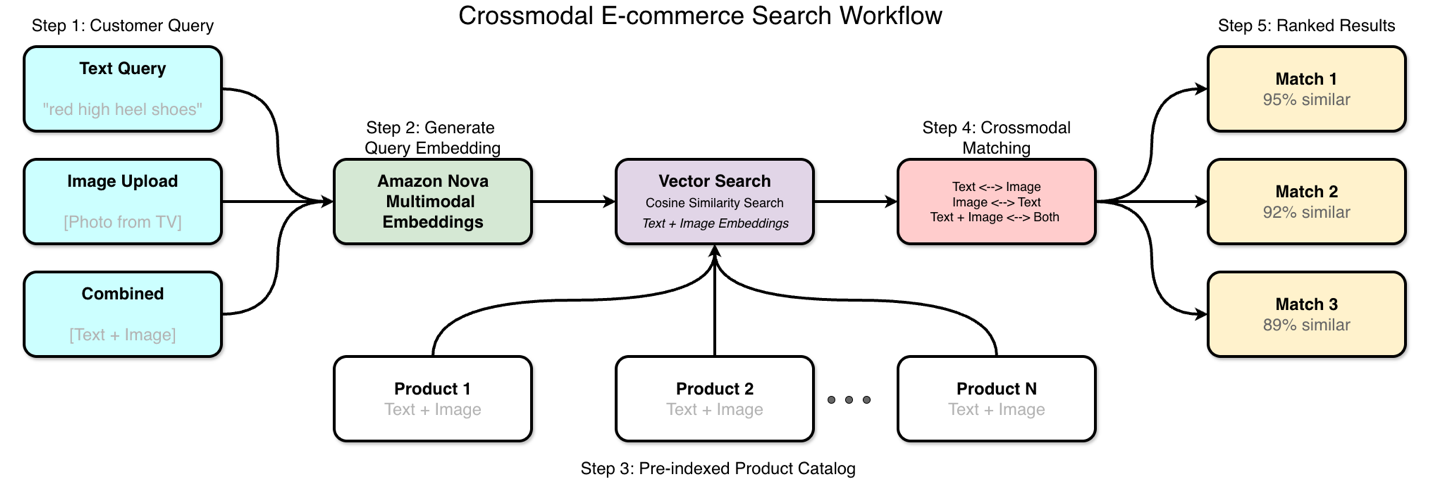
Amazon Nova 多模态嵌入如何提供帮助
Amazon Nova 通过同一个模型处理不同类型的搜索查询,这带来了新的搜索功能和技术优势。无论您是上传图像、输入文本描述,还是两者结合,处理过程都是相同的。
跨模态搜索功能
如前所述,Amazon Nova 多模态嵌入通过统一的模型架构处理所有支持的模态。输入内容可以是文本、图像、文档、视频或音频,然后它会在相同的向量空间中生成嵌入。这支持不同内容类型之间的直接相似性计算,而无需额外的转换层。当客户上传图像时,系统会将它们转换为嵌入,并使用余弦相似度针对产品目录进行搜索。您将获得具有相似视觉特征的产品,无论它们在文本中的描述方式如何。文本查询的工作方式相同——客户可以描述他们想要的内容,并找到视觉上相似的产品,即使产品描述使用了不同的词语。如果客户上传带有文本描述的图像,系统会通过同一嵌入模型处理这两个输入,以获得统一的相似度评分。该系统还通过自动产品标记从图像中提取产品属性,支持超越手动分类的语义标签生成。
技术优势
与独立的文本和图像嵌入相比,统一的架构具有多项优势。单一模型设计和共享的语义空间解锁了管理多个嵌入系统无法实现的新用例。应用程序使用相同的 API 端点和向量维度为所有内容类型生成嵌入。一个模型可以处理所有五个模态,因此相关内容(如产品图像及其描述)会产生相似的嵌入。您可以计算文本、图像、音频和视频任何组合之间的距离,以衡量它们的相似程度。
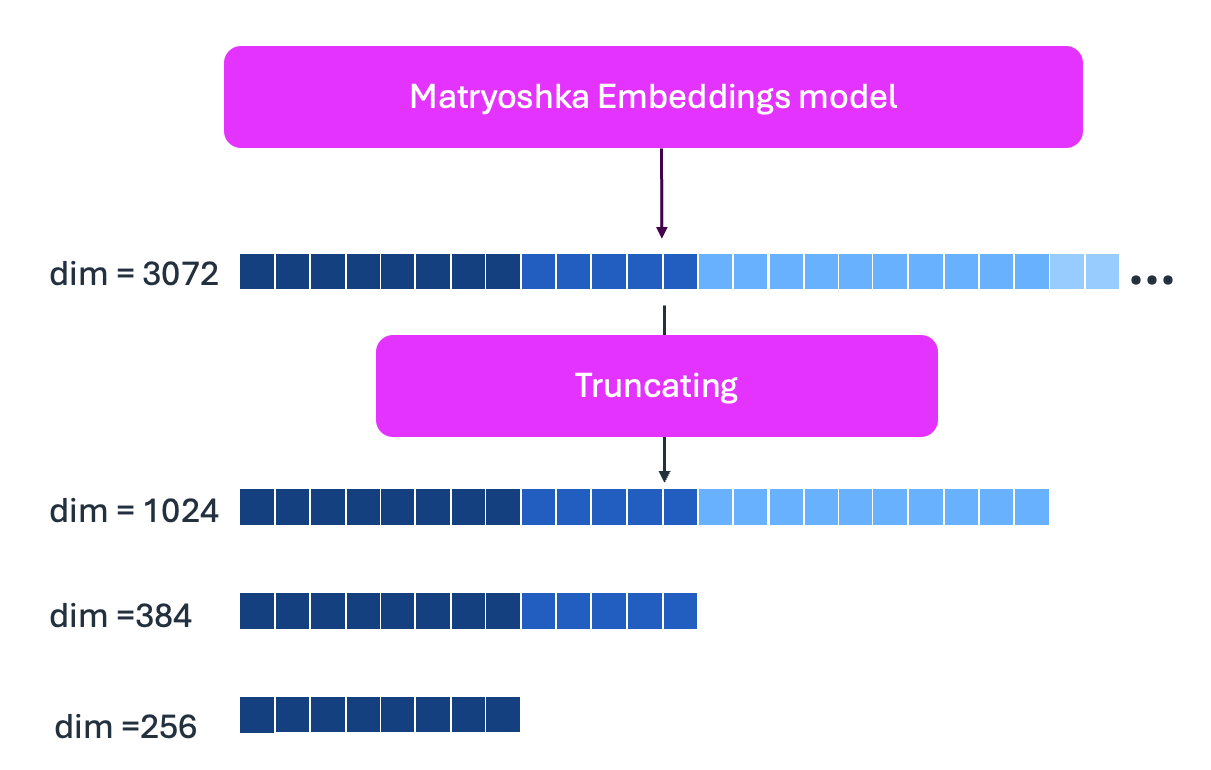
Amazon Nova 多模态嵌入模型使用 Matryoshka 表示学习,支持多种嵌入维度:3072、1024、384 和 256。Matryoshka 嵌入学习将最重要的信息存储在最前面的维度中,将不太关键的细节存储在后面的维度中。您可以从末尾截断(如下所示),以减小存储空间,同时为您的特定用例保持准确性。
架构
构建这种方法需要三个主要组件:嵌入生成、向量存储和相似性搜索。产品目录经过预处理以生成所有内容类型的嵌入。查询处理使用相同的模型将用户输入转换为嵌入。相似性搜索将查询嵌入与存储的产品嵌入进行比较,如下图所示。
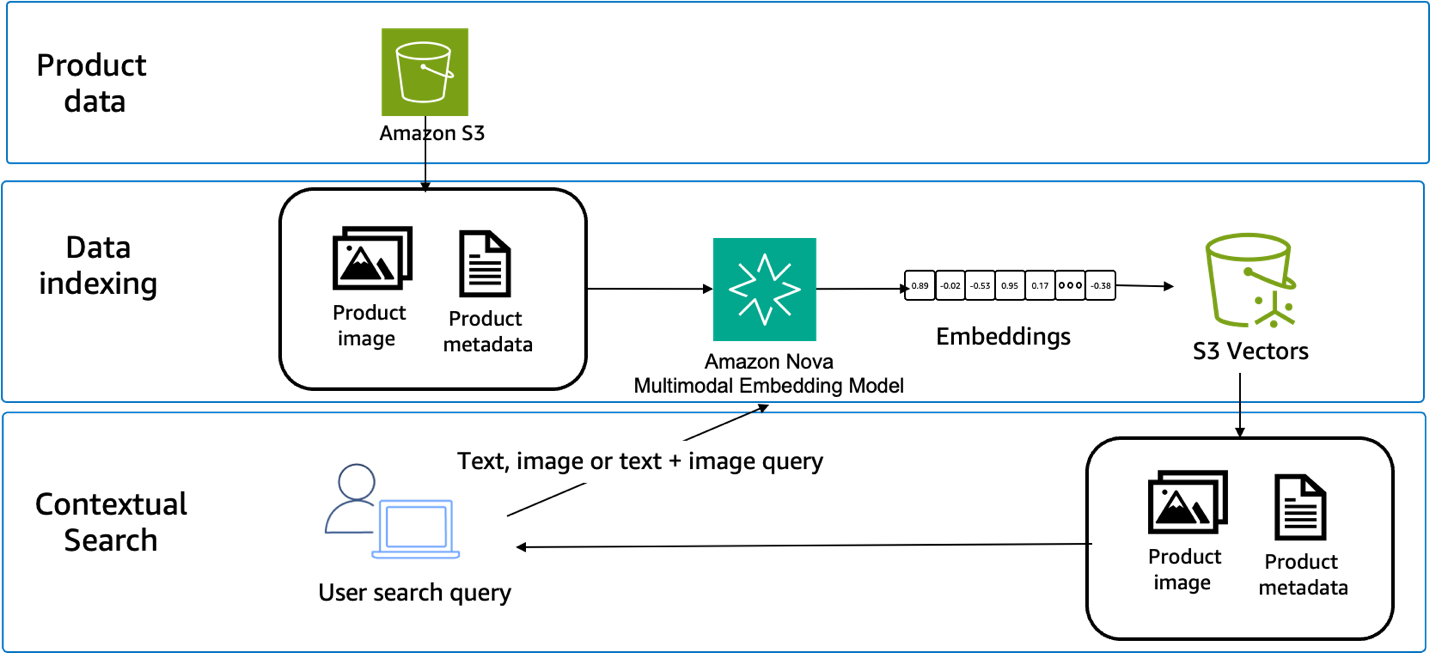
向量存储系统必须支持所选的嵌入维度,并提供高效的相似性搜索操作。选项包括专用的向量数据库、带有向量扩展的传统数据库,或以云为中心的向量服务,例如 Amazon S3 Vectors——Amazon S3 的一项功能,可以直接在 S3 中原生支持存储和查询向量嵌入。
先决条件
要有效地使用此功能,此实现需要满足一些关键方面。一个具有 Amazon Bedrock 访问权限的 AWS 账户,以便访问 Amazon Nova 多模态嵌入模型。其他需要的服务包括 S3 Vectors。您可以按照我们 Amazon Nova 示例 存储库中可用的笔记本进行操作。
实施
在接下来的部分中,我们将跳过初始数据下载和提取步骤,但完整的端到端方法可在笔记本中供您参考。省略的步骤包括下载 Amazon Berkeley Objects (ABO) 数据集存档,其中包含产品元数据、目录图像和 3D 模型。这些存档需要提取和预处理,以解析来自压缩 JSON 和 tar 文件的大约 398,212 张图像和 9,232 个产品列表。提取后,数据需要对产品描述与其相应的视觉资产之间的元数据进行对齐。在完成这些初步步骤后,我们开始本次演练,重点关注核心工作流程:设置 S3 Vectors、使用 Amazon Nova 多模态嵌入生成嵌入、大规模存储向量以及实现跨模态检索。我们开始吧。
S3 Vector 存储桶和索引创建:
为嵌入创建向量存储基础设施。S3 Vectors 是一项用于大规模存储和查询高维向量的托管服务。存储桶充当向量数据的容器,而索引定义了结构和搜索特性。我们将索引配置为使用余弦距离度量,它根据向量方向而非幅度来衡量相似性,非常适合 Amazon Nova 多模态嵌入等服务提供的标准化嵌入。
*# S3 Vectors configuration*
s3vector_bucket = "amzn-s3-demo-vector-bucket-crossmodal-search"
s3vector_index = "product"
embedding_dimension = 1024
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
*# Create S3 vector bucket*
s3vectors.create_vector_bucket(vectorBucketName=s3vector_bucket)
*# Create index*
s3vectors.create_index( vectorBucketName=s3vector_bucket, indexName=s3vector_index, dataType='float32', dimension=embedding_dimension, distanceMetric='cosine'
)
产品目录预处理:
在这里我们生成嵌入。产品图像和文本描述都需要进行嵌入生成,并存储带有适当元数据以供检索。Amazon Nova Embeddings API 独立处理每种模态,将文本描述和产品图像转换为 1024 维向量。这些向量存在于统一的语义空间中,这意味着同一产品的文本嵌入和图像嵌入将在几何上彼此靠近。
# Initialize Nova Embeddings Client
class NovaEmbeddings:
def __init__(self, region='us-east-1'):
self.bedrock = boto3.client('bedrock-runtime', region_name=region)
self.model_id = "amazon.nova-2-multimodal-embeddings-v1:0"
def embed_text(self, text: str, dimension: int = 1024, purpose: str = "GENERIC_INDEX"):
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": dimension,
"embeddingPurpose": purpose,
"text": {
"truncationMode": "END",
"value": text
}
}
}
response = self.bedrock.invoke_model(modelId=self.model_id, body=json.dumps(request_body))
result = json.loads(response['body'].read())
return result['embeddings'][0]['embedding']
def embed_image(self, image_bytes: bytes, dimension: int = 1024, purpose: str = "GENERIC_INDEX"):
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": dimension,
"embeddingPurpose": purpose,
"image": {
"format": "jpeg",
"source": {"bytes": base64.b64encode(image_bytes).decode()}
}
}
}
response = self.bedrock.invoke_model(modelId=self.model_id, body=json.dumps(request_body))
result = json.loads(response['body'].read())
return result['embeddings'][0]['embedding']
embeddings = NovaEmbeddings()
我们使用以下代码生成嵌入并将数据上传到我们的向量存储中。
# Generate embeddings and upload to Amazon S3 Vectors
def get_product_text(product):
name = product.get('item_name', [{}])[0].get('value', '') if isinstance(product.get('item_name'), list) else str(product.get('item_name', ''))
brand = product.get('brand', [{}])[0].get('value', '') if product.get('brand') else ''
return f"{name}. {brand}".strip()
vectors_to_upload = []
batch_size = 10
catalog = [] # Keep for local reference
for product in tqdm(sampled_products, desc="Processing products"):
img_path = get_image_path(product)
text = get_product_text(product)
product_id = product.get('item_id', str(len(catalog)))
with open(img_path, 'rb') as f:
img_bytes = f.read()
# Generate embeddings
text_emb = embeddings.embed_text(text)
image_emb = embeddings.embed_image(img_bytes)
# Store in catalog for local use
catalog.append({
'text': text,
'image_path': str(img_path),
'text_emb': text_emb,
'image_emb': image_emb,
'product_id': product_id
})
# Prepare vectors for S3 upload
vectors_to_upload.extend([
{
"key": f"text-{product_id}",
"data": {"float32": text_emb},
"metadata": {"product_id": product_id, "text": text, "image_path": str(img_path), "type": "text"}
},
{
"key": f"image-{product_id}",
"data": {"float32": image_emb},
"metadata": {"product_id": product_id, "text": text, "image_path": str(img_path), "type": "image"}
},
{
"key": f"combined-{product_id}",
"data": {"float32": np.mean([text_emb, image_emb], axis=0).tolist()},
"metadata": {"product_id": product_id, "text": text, "image_path": str(img_path), "type": "combined"}
}
])
# Batch upload
if len(vectors_to_upload) >= batch_size * 3:
s3vectors.put_vectors(vectorBucketName=s3vector_bucket, indexName=s3vector_index, vectors=vectors_to_upload)
vectors_to_upload = []
# Upload remaining vectors
if vectors_to_upload:
s3vectors.put_vectors(vectorBucketName=s3vector_bucket, indexName=s3vector_index, vectors=vectors_to_upload)
查询处理:
此代码通过 API 处理客户输入。文本查询、图像上传或它们的组合都会转换为与产品目录相同的向量格式。对于结合了文本和图像的多模态查询,我们应用平均融合来创建一个捕获两种模态信息的单个查询向量。查询处理逻辑处理三种不同的输入类型,并准备适当的嵌入表示,以便与 S3 Vectors 索引进行相似性搜索。
def search_s3(query=None, query_image=None, query_type='text', search_mode='combined', top_k=5):
""" Search using S3 Vectors
query_type: 'text', 'image', or 'both'
search_mode: 'text', 'image', or 'combined'
"""
# Get query embedding
if query_type == 'both':
text_emb = embeddings.embed_text(query)
with open(query_image, 'rb') as f:
image_emb = embeddings.embed_image(f.read())
query_emb = np.mean([text_emb, image_emb], axis=0).tolist()
query_image_path = query_image
elif query_type == 'text':
query_emb = embeddings.embed_text(query)
query_image_path = None
else:
with open(query_image, 'rb') as f:
query_emb = embeddings.embed_image(f.read())
query_image_path = query_image
向量相似性搜索:
接下来,我们使用 S3 Vectors 查询 API 添加跨模态检索。系统会查找与查询最接近的嵌入匹配项,无论查询是文本还是图像。我们使用余弦相似度作为距离度量,它衡量向量之间的角度而非绝对距离。这种方法非常适合标准化嵌入,并且资源效率高,非常适合与近似最近邻算法配对的大型目录。S3 Vectors 负责索引和搜索基础设施,因此您可以专注于应用程序逻辑,而服务则管理可扩展性和性能优化。
# Query S3 Vectors
response = s3vectors.query_vectors(
vectorBucketName=s3vector_bucket,
indexName=s3vector_index,
queryVector={"float32": query_emb},
topK=top_k,
returnDistance=True,
returnMetadata=True,
filter={"metadata.type": {"equals": search_mode}}
)
结果排序:
S3 Vectors 计算的相似度分数提供了排序机制。查询嵌入与目录嵌入之间的余弦相似度决定了结果顺序,分数越高表示匹配度越好。在生产系统中,您通常会收集点击率数据和相关性判断,以验证排序是否与实际用户行为相关。S3 Vectors 返回距离值,我们将其转换为相似度分数(1 – 距离)以便于理解,其中较高的值表示更接近的匹配。
# Extract and rank results by similarity
ranked_results = []
for result in response['vectors']:
metadata = result['metadata']
distance = result.get('distance', 0)
similarity = 1 - distance # Convert distance to similarity score
ranked_results.append({
'product_id': metadata['product_id'],
'text': metadata['text'],
'image_path': metadata['image_path'],
'similarity': similarity,
'distance': distance
})
# Results are sorted by S3 Vectors (best matches first)
return ranked_results
结论
Amazon Nova 多模态嵌入通过使用一个模型而非管理多个独立系统解决了跨模态搜索的核心问题。您可以使用 Amazon Nova 多模态嵌入来构建搜索系统,无论客户是上传图像、以文本形式输入描述,还是将这两种方法结合起来,该系统都能正常工作。
使用 Amazon Bedrock API 进行实现非常简单,而 Matryoshka 嵌入维度可让您根据特定的准确性和成本要求进行优化。如果您正在构建电子商务搜索、内容发现或用户需要与多种内容类型交互的应用程序,这种统一的方法可以减少开发复杂性和运营开销。
Matryoshka 表示学习在不同维度上保持了嵌入质量 [2]。性能下降遵循可预测的模式,允许应用程序针对特定用例进行优化。
后续步骤
Amazon Nova 多模态嵌入现已在 Amazon Bedrock 中可用。请参阅 使用 Nova 嵌入 以获取 API 引用、代码示例和常见架构的集成模式。
AWS 示例存储库中的 AWS 示例存储库 包含有关多模态嵌入的实现示例。
在此处试用此特定电子商务示例笔记本
关于作者
 Tony Santiago 是 AWS 的全球合作伙伴解决方案架构师,致力于在大型系统集成商中推广生成式 AI 的采用。他专注于解决方案构建、技术上市战略和能力开发——赋能 GSI 合作伙伴中数以万计的构建者为其客户提供由 AI 驱动的解决方案。凭借超过 20 年的全球技术经验和在 AWS 的十年经验,Tony 倡导能够带来可衡量业务成果的实用技术。工作之余,他热衷于学习新事物和与家人共度时光。
Tony Santiago 是 AWS 的全球合作伙伴解决方案架构师,致力于在大型系统集成商中推广生成式 AI 的采用。他专注于解决方案构建、技术上市战略和能力开发——赋能 GSI 合作伙伴中数以万计的构建者为其客户提供由 AI 驱动的解决方案。凭借超过 20 年的全球技术经验和在 AWS 的十年经验,Tony 倡导能够带来可衡量业务成果的实用技术。工作之余,他热衷于学习新事物和与家人共度时光。
 Adewale Akinfaderin 是 Amazon Bedrock 生成式 AI 部门的高级数据科学家,他在 AWS 致力于基础模型和生成式 AI 应用的前沿创新。他的专长在于可复现和端到端的 AI/ML 方法、实际实现,以及帮助全球客户制定和开发可扩展的解决方案来解决跨学科问题。他拥有物理学两个研究生学位和工程学博士学位。
Adewale Akinfaderin 是 Amazon Bedrock 生成式 AI 部门的高级数据科学家,他在 AWS 致力于基础模型和生成式 AI 应用的前沿创新。他的专长在于可复现和端到端的 AI/ML 方法、实际实现,以及帮助全球客户制定和开发可扩展的解决方案来解决跨学科问题。他拥有物理学两个研究生学位和工程学博士学位。
 Sharon Li 是 AWS 的一名解决方案架构师,驻扎在马萨诸塞州波士顿地区。她与企业客户合作,帮助他们解决难题并在 AWS 上进行构建。工作之余,她喜欢与家人共度时光和探索当地餐馆。
Sharon Li 是 AWS 的一名解决方案架构师,驻扎在马萨诸塞州波士顿地区。她与企业客户合作,帮助他们解决难题并在 AWS 上进行构建。工作之余,她喜欢与家人共度时光和探索当地餐馆。
 Sundaresh R. Iyer 是 Amazon Web Services (AWS) 的合作伙伴解决方案架构师,他与渠道合作伙伴和系统集成商紧密合作,设计、扩展和部署生成式 AI 和智能体架构。凭借超过 15 年的产品管理、开发人员平台和云基础设施经验,他专注于机器学习和 AI 驱动的开发人员工具。Sundaresh 热衷于通过构建安全、受治理和可扩展的 AI 系统来帮助合作伙伴从实验走向生产,从而实现可衡量的业务成果。
Sundaresh R. Iyer 是 Amazon Web Services (AWS) 的合作伙伴解决方案架构师,他与渠道合作伙伴和系统集成商紧密合作,设计、扩展和部署生成式 AI 和智能体架构。凭借超过 15 年的产品管理、开发人员平台和云基础设施经验,他专注于机器学习和 AI 驱动的开发人员工具。Sundaresh 热衷于通过构建安全、受治理和可扩展的 AI 系统来帮助合作伙伴从实验走向生产,从而实现可衡量的业务成果。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区