



📢 转载信息
原文作者:Yicheng Shen, Sarathy Varadarajan, Ameer Hakme, Gene Su, Dipanshu Jain, Joe King, and Priyashree Roy
New Relic Inc. 是一家总部位于旧金山的技术公司,开创了应用性能监控 (APM) 领域,并提供全面的可观测性解决方案。New Relic 为包括 Ryanair 在内的全球领先客户提供服务,帮助组织监控和优化其数字系统,以提供更出色的客户体验。
New Relic 面临着许多快速发展的企业都面临的一个挑战。他们的工程师花费宝贵的时间在跨多个系统的零散文档中进行搜索,耗时的内部系统查询有时需要一天以上的时间。作为支持全球数千个客户的领先可观测性平台,New Relic 知道需要一种更高效的方式来访问和利用组织知识。
这一挑战催生了 New Relic NOVA(New Relic 全方位虚拟助手):一个基于 Amazon Web Services (AWS) 构建的创新人工智能 (AI) 工具。New Relic NOVA 彻底改变了 New Relic 员工访问和与公司知识及系统交互的方式。
通过与 生成式 AI 创新中心合作,New Relic NOVA 从一个知识助手发展成为一个全面的生产力引擎。New Relic NOVA 基于 AWS 服务构建,包括 Amazon Bedrock、Amazon Kendra、Amazon Simple Storage Service (Amazon S3) 和 Amazon DynamoDB。通过 Strands Agents,New Relic NOVA 提供智能代码审查、AI 治理和托管的模型上下文协议 (MCP) 服务。
Amazon Bedrock 是一项完全托管的服务,提供对领先的基础模型的访问,用于构建生成式 AI 应用程序,无需管理基础设施,同时使团队能够根据其特定用例定制模型。通过单一 API,开发人员可以试验和评估不同的基础模型,将它们与企业系统集成,并以规模构建安全的 AI 应用程序。
该解决方案减少了信息搜索时间,同时自动化了复杂的操作工作流程。通过与生成式 AI 创新中心的合作,New Relic NOVA 已发展成为一个解决方案,目前在整个组织中处理超过 1,000 次每日查询。New Relic NOVA 与 Confluence、GitHub、Salesforce、Slack 以及各种内部系统无缝集成,在知识查询和事务性任务的响应准确率方面保持 80%。
我们将展示 New Relic NOVA 如何使用 AWS 服务构建架构,以创建可扩展的智能助手,该助手不仅可以进行文档检索,还可以处理复杂的任务,例如自动化的团队权限请求和速率限制管理。我们将探讨构建能够以规模实现可衡量生产力提升的企业级 AI 解决方案时的技术架构、开发历程和关键经验教训。
解决方案概述
在设计 New Relic NOVA 时,New Relic 确定了除最初改进文档搜索目标之外的几个关键目标。这些目标包括在知识检索期间维护数据安全,以及在不同数据源之间保持一致的响应质量。如图 1 所示,New Relic NOVA 的 AWS 架构实现了用户与各种 AWS 服务之间的无缝交互,同时保持了安全性和可扩展性。该解决方案需要一个灵活的框架,该框架可以随着组织对知识检索和事务性任务的需求而发展。一个关键挑战是在保持响应时间低于 20 秒以维持用户参与度的同时平衡这些要求。
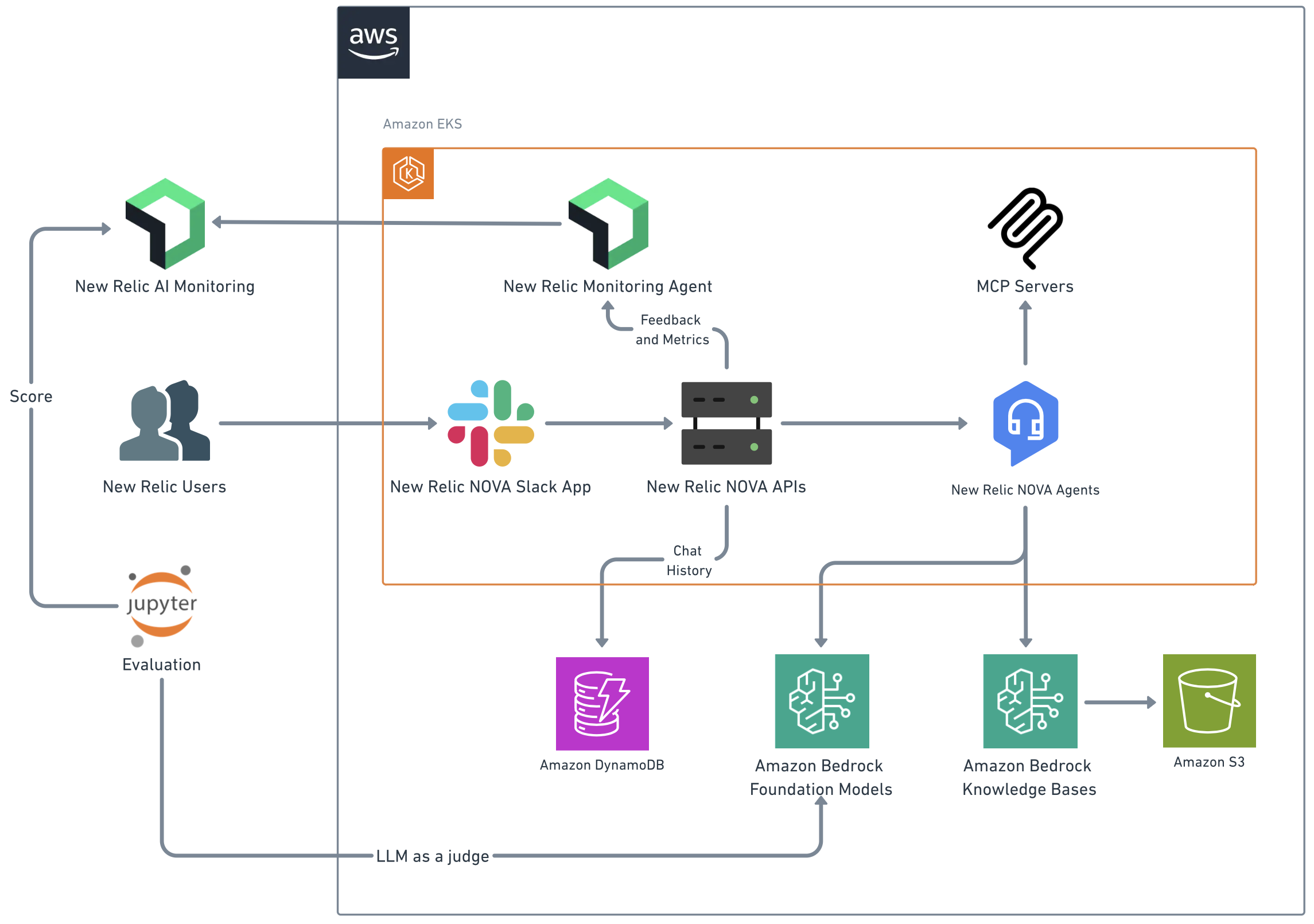
图 1 – New Relic NOVA 框架的解决方案架构
开发团队在项目早期确定了几个潜在风险。这些风险包括 AI 响应可能泄露敏感信息、从多个数据源检索时保持准确性,以及确保系统在企业规模下的可靠性。图 2 演示了 New Relic NOVA 的详细代理工作流程,展示了查询如何通过各种专业代理进行处理和路由,以解决用户意图。此外,团队实施了全面的安全控制,包括个人身份信息 (PII) 检测和屏蔽,以及一个强大的评估框架来监控和维护响应质量。
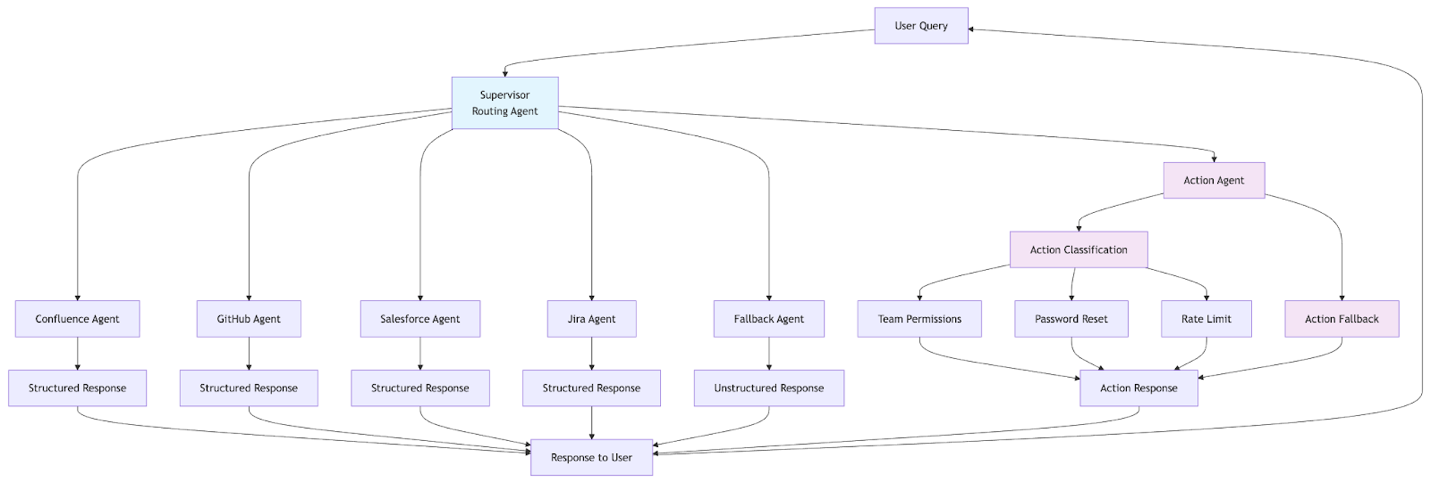
图 2 – New Relic NOVA 代理工作流程架构
该项目还揭示了未来优化的机会。这些机会包括扩展代理层级架构以支持额外的自动化工作流程,以及开发更复杂的分析工具来跟踪用户交互模式。该团队的经验表明,进行类似项目的组织应尽早着眼于建立明确的评估指标,并构建能够适应不断变化的业务需求的灵活架构。
解决方案
New Relic NOVA 在八周内开发完成,涉及 New Relic 内部工程、安全、法律和合规团队与 AWS 生成式 AI 创新中心之间的协作。这次合作加速了快速开发和迭代,利用了 AWS 在大规模 AI 实施方面的专业知识。
代理架构
New Relic NOVA 的架构包含三个关键层:
- 主代理层 – 这充当可控的编排层,通过识别用户意图并将工作委托给以下下游层来执行不同的工作流程:
- 检索增强生成 (RAG),使用来自 Amazon Bedrock 知识库或 Amazon Kendra 的定制摄取知识。
- 用于与第三方平台直接交互的代理。
- 用于处理 New Relic 内部任务的定制代理。
- 在无法确定用户响应时进行后备处理。
- 数据源层(向量数据库、丰富、数据源) – 这些层代表内部知识(例如,New Relic 标准文档和代码存储库文档)被摄取以用于检索或 RAG 的资源。这些定制资源的优势在于增强了信息和搜索性能,以满足信息请求。
- 代理层 – 由两种不同的代理类型组成:
- 带 MCP 的 Strands Agents:处理第三方服务的多步骤流程,利用 MCP 进行标准化服务交互。
- 自定义操作代理:执行 New Relic 特定的任务,例如权限请求和服务限制修改,提供对内部系统的精确控制。
一个中央代理充当编排器,以委托模式将查询路由到专门的子代理,其中响应直接返回给用户,而无需进行代理间推理或调整。同时,Strands Agents 用于利用 MCP 有效地管理第三方服务集成。这种方法为 New Relic 带来了两全其美的好处:编排模型为内部流程保持了灵活性,同时通过 MCP 标准化了外部服务,为 New Relic 的未来自动化需求奠定了可扩展的基础。
数据集成策略
其强大之处在于 New Relic NOVA 能够无缝集成多个数据源,为知识检索提供统一的接口。这种方法包括:
- Amazon Bedrock 知识库 for Confluence:确认与 Confluence 空间的直接同步并保持最新信息。
- Amazon Kendra for GitHub Enterprise:对 GitHub 存储库进行索引和搜索,快速访问代码文档。
- Strands Agents for Salesforce and Jira:自定义代理分别执行 SOQL 和 JQL 查询,以从各自的平台(Salesforce 和 Jira)获取相关数据。
- Amazon Q Index for Slack:利用 Amazon Q Index 功能对 Slack 频道历史记录实施 RAG 解决方案,选择它的原因是其快速开发潜力。
New Relic NOVA 数据集成的独特之处在于定制文档富集过程。在摄取过程中,文档会使用元数据、关键词和摘要进行增强,从而显著提高了检索的相关性和准确性。
使用 Amazon Nova 模型
Amazon Nova 是 AWS 的新一代基础模型,旨在为企业用例提供具有行业领先价格性能的前沿智能。Amazon Nova 模型家族可以处理包括文本、图像和视频在内的多样化输入,在从交互式聊天到文档分析等任务中表现出色,同时支持 RAG 系统和 AI 代理工作流程等高级功能。
为了优化性能和成本效益,New Relic NOVA 通过 Amazon Bedrock 利用 Amazon Nova Lite 和 Pro 模型。这些模型经过精心挑选,以平衡响应质量和延迟,使 New Relic NOVA 能够在处理复杂查询时将响应时间保持在 20 秒以内。Amazon Bedrock 提供了对各种 基础模型家族的访问。其标准化框架和提示优化支持在不更改代码的情况下在模型之间无缝切换。这使得 New Relic NOVA 能够使用 Amazon Nova Lite 针对速度进行优化,或者根据复杂性切换到 Amazon Nova Pro,同时保持一致的性能和成本效益。
高级 RAG 实施
New Relic NOVA 采用复杂的 RAG 方法,利用 Amazon Bedrock 知识库、Amazon Kendra 和 Amazon Q Index。为了最大限度地提高检索准确性,New Relic NOVA 实施了几项关键优化技术:
- 分层分块(Hierarchical chunking):Amazon Bedrock 知识库采用分层分块技术,这种方法经过对各种分块方法的广泛实验证明是最有效的。
- 上下文富集:一个定制的 AWS Lambda 函数在知识库摄取期间增强分块,并纳入相关的关键词和上下文信息。此过程对于代码相关内容尤其有价值,因为结构和语义线索会显著影响检索性能。
- 元数据集成:在知识库文档摄取过程中,额外的上下文(如摘要、标题、作者、创建日期和最后修改日期)作为文档元数据附加。这种丰富的元数据提高了检索信息的质量和相关性。
- 定制文档处理:对于 GitHub 存储库等特定数据源,应用定制的文档处理技术以保持代码结构并提高搜索相关性。
这些技术协同工作,优化了 New Relic NOVA 中的 RAG 系统,在不同文档类型中提供高度准确的检索,同时通过现有连接器最大限度地减少开发工作量。分层分块、上下文富集、元数据集成和定制文档处理的结合,使 New Relic NOVA 无论数据源或文档格式如何,都能提供精确、上下文感知的响应。
评估框架
New Relic NOVA 实施了一个全面的评估框架,利用 Amazon Bedrock 基础模型进行其 “LLM 即裁判”(LLM-as-a-judge)方法,以及结合了问题、事实真相答案和源文档 URL 的验证数据集。此评估框架可在开发环境中按需执行,涵盖了系统验证的三个关键指标:
- 答案准确性衡量利用 1–5 的离散量表评分系统,其中 LLM 根据既定的事实真相数据评估生成的响应的事实一致性。
- 上下文相关性评估在 1–5 的范围内进行,分析检索到的上下文与用户查询的相关性。
- 响应延迟跟踪衡量工作流程性能,从初始查询输入到最终答案生成,通过全面的时间分析确保最佳用户体验。
这种三重指标评估方法支持对 New Relic NOVA 解决方案核心功能进行详细的性能优化。
可观测性和持续改进
该解决方案包括一个全面的可观测性框架,用于收集指标和分析用户反馈。指标和反馈收集是通过 New Relic AI 监控解决方案实现的。反馈通过 Slack 的反应功能(表情符号响应)实现,用户可以快速对 New Relic NOVA 的响应提供反馈。这些反应由 New Relic Python 代理捕获并发送到 https://one.newrelic.com/ 域。反馈收集系统提供了有价值的见解,用于:
- 衡量用户对响应的满意度。
- 确定可以提高准确性的领域。
- 了解跨不同团队的使用模式。
- 跟踪不同类型查询的有效性。
- 监控各种数据源的性能。
- 跟踪每次 LLM 调用和延迟。
收集的反馈数据可以使用 AWS 分析服务进行分析,例如 AWS Glue 进行 ETL 处理、Amazon Athena 进行查询,以及 Amazon QuickSight 进行可视化。这种数据驱动的方法能够持续改进 New Relic NOVA,并根据实际用户交互情况帮助确定未来增强的优先级。
内部团队已经体验到了 New Relic NOVA 的优势。图 3 展示了通过 Slack 反馈流程捕获的一些响应。
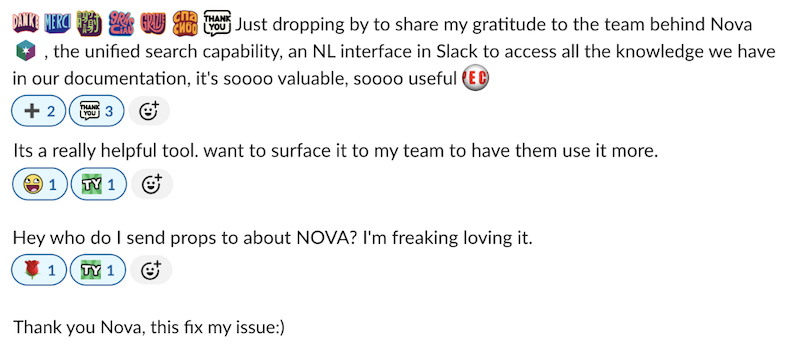
图 3 – 用户关于 New Relic NOVA 体验的 Slack 消息交流
考量与后续步骤
New Relic NOVA 的成功突显了希望实施类似解决方案的组织应注意的几个关键经验教训:
- 从清楚了解用户痛点和可衡量的成功标准开始。
- 实施稳健的数据集成策略,并进行定制的文档富集。
- 使用最适合您用例的生成式 AI 服务和基础模型,以实现最佳结果。
- 从一开始就构建反馈机制,以实现持续改进。
- 同时关注速度和准确性,以确保用户采纳。
在后续步骤方面,New Relic NOVA 正通过集成最新的 AWS 技术和开源框架,从一个独立的解决方案演变为一个全面的企业 AI 平台。未来,New Relic 计划利用 Amazon S3 Vectors。与传统方法相比,它在向量存储和查询方面提供了高达 90% 的成本降低,从而能够更高效地处理大规模 AI 工作负载。New Relic 正在研究 Amazon Bedrock AgentCore,以实现企业级的安全、内存管理和可扩展的 AI 代理部署,支持稳健的生产能力。
此外,New Relic 正在探索 Strands Agent Workflows,这是一个开源 SDK,可以简化从简单的对话助手到复杂的自主工作流程的 AI 代理构建。这个技术栈使 New Relic NOVA 能够提供企业级的 AI 解决方案,这些方案可以无缝扩展,同时保持成本效益和开发人员的生产力。
结论
创建 New Relic NOVA 的历程展示了企业如何利用 AWS 的生成式 AI 服务来转型组织生产力。通过集成 Amazon Bedrock、Amazon Kendra 和其他 AWS 服务,New Relic 创建了一个变革其内部运营的 AI 助手。通过与 AWS 生成式 AI 创新中心合作,New Relic 在整个组织中将信息搜索时间减少了 95%,同时自动化了复杂的操作工作流程。
要了解有关利用生成式 AI 转型业务的更多信息,请访问 生成式 AI 创新中心,或咨询 AWS 合作伙伴专家或 AWS 代表,了解我们如何帮助加速您的业务。
进一步阅读
- 在 AWS 上构建生成式 AI 应用程序 – AWS 课堂培训
- 生成式 AI 镜头 – AWS 最佳实践框架 – 深入了解如何在 AWS 上有效设计、部署和操作生成式 AI 应用程序
- 使用 Amazon Bedrock 知识库和 AWS CloudFormation 构建端到端 RAG 解决方案
- 代理互操作性的开放协议第 1 部分:MCP 上的代理间通信
作者简介
 Yicheng Shen 是 New Relic NOVA 的首席软件工程师,专注于开发改变企业理解其应用性能的方式的生成式 AI 和代理解决方案。当他不构建智能系统时,你会发现他和家人以及他们的狗在户外探索。
Yicheng Shen 是 New Relic NOVA 的首席软件工程师,专注于开发改变企业理解其应用性能的方式的生成式 AI 和代理解决方案。当他不构建智能系统时,你会发现他和家人以及他们的狗在户外探索。
 Sarathy Varadarajan,New Relic 工程高级总监,推动 AI 优先转型和开发人员生产力,目标是通过智能自动化和企业 AI 实现十倍的提升。他将班加罗尔和海得拉巴的工程团队从 15 人扩展到 350 多人。他喜欢家庭时光和排球。
Sarathy Varadarajan,New Relic 工程高级总监,推动 AI 优先转型和开发人员生产力,目标是通过智能自动化和企业 AI 实现十倍的提升。他将班加罗尔和海得拉巴的工程团队从 15 人扩展到 350 多人。他喜欢家庭时光和排球。
 Joe King 是生成式 AI 创新中心的 AWS 高级数据科学家,他帮助组织架构和实施尖端的生成式 AI 解决方案。凭借在科学、工程和 AI/ML 架构方面的深厚专业知识,他专注于将复杂的生成式 AI 用例转化为 AWS 上的可扩展解决方案。
Joe King 是生成式 AI 创新中心的 AWS 高级数据科学家,他帮助组织架构和实施尖端的生成式 AI 解决方案。凭借在科学、工程和 AI/ML 架构方面的深厚专业知识,他专注于将复杂的生成式 AI 用例转化为 AWS 上的可扩展解决方案。
 Priyashree Roy 是生成式 AI 创新中心的 AWS 数据科学家,她在其中运用自己在机器学习和生成式 AI 方面的深厚专业知识,为 AWS 战略客户构建尖端解决方案。她拥有实验粒子物理学博士学位,为通过先进的 AI 技术解决复杂的现实问题带来了严谨的科学方法。
Priyashree Roy 是生成式 AI 创新中心的 AWS 数据科学家,她在其中运用自己在机器学习和生成式 AI 方面的深厚专业知识,为 AWS 战略客户构建尖端解决方案。她拥有实验粒子物理学博士学位,为通过先进的 AI 技术解决复杂的现实问题带来了严谨的科学方法。
 Gene Su 是 AWS 生成式 AI 创新中心的数据科学家,专注于金融、零售和其他行业的生成式 AI 解决方案。他利用自己在大型语言模型 (LLM) 方面的专业知识,在 AWS 上交付生成式 AI 应用程序。
Gene Su 是 AWS 生成式 AI 创新中心的数据科学家,专注于金融、零售和其他行业的生成式 AI 解决方案。他利用自己在大型语言模型 (LLM) 方面的专业知识,在 AWS 上交付生成式 AI 应用程序。
 Dipanshu Jain 是 AWS 的生成式 AI 战略顾问,通过战略咨询和定制解决方案开发来释放生成式 AI 的潜力。他专注于识别高影响力的生成式 AI 用例,制定执行路线图,并指导跨职能团队完成概念验证——从发现到生产。
Dipanshu Jain 是 AWS 的生成式 AI 战略顾问,通过战略咨询和定制解决方案开发来释放生成式 AI 的潜力。他专注于识别高影响力的生成式 AI 用例,制定执行路线图,并指导跨职能团队完成概念验证——从发现到生产。
 Ameer Hakme 是 AWS 解决方案架构师,与东北地区独立软件供应商 (ISV) 合作,协助设计和构建 AWS 云上可扩展和现代化的平台。作为 AI/ML 和生成式 AI 专家,Ameer 帮助客户释放这些尖端技术的潜力。在休闲时间,他喜欢骑摩托车和与家人共度美好时光。
Ameer Hakme 是 AWS 解决方案架构师,与东北地区独立软件供应商 (ISV) 合作,协助设计和构建 AWS 云上可扩展和现代化的平台。作为 AI/ML 和生成式 AI 专家,Ameer 帮助客户释放这些尖端技术的潜力。在休闲时间,他喜欢骑摩托车和与家人共度美好时光。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区