



📢 转载信息
原文作者:Aman Sharma, Suraj Padinjarute, and Surjit Reghunathan
如果您在规模化管理物联网(IoT)设备,那么警报疲劳可能会削弱您系统的有效性。本文将向您展示如何利用Amazon Bedrock及其生成式AI功能来实现智能通知过滤。您将学习模型选择策略、成本优化技术以及基于Swann Communications在全球数百万设备上的部署实践,了解在物联网规模上部署生成式AI的架构模式。
智能家居安全客户现在期望系统不仅能检测到运动,还能区分送货员和潜在的入侵者。客户们被大量的日常通知或误报淹没,许多警报是由与客户不相关的事件触发的,例如路过的汽车、四处移动的宠物等。用户对持续的误报感到沮丧,并开始完全忽略通知,甚至包括真正的安全威胁。
作为DIY(自己动手做)安全解决方案的先驱,Swann Communications已经建立了覆盖超过1174万台联网设备的全球网络,为多大洲的房主和企业提供服务。Swann与Amazon Web Services (AWS)合作,开发了一个多模型生成式AI通知系统,旨在将其通知系统从基本的、被动的警报机制,演变为智能的、情境感知的安全助手。
驱动解决方案的业务挑战
在实施新解决方案之前,Swann面临着几项关键挑战,这些挑战需要对安全通知采取根本不同的方法。
Swann之前的系统只有基本的检测能力,只能识别人类或宠物事件,缺乏情境感知能力——将送货员与潜在入侵者一视同仁,同时不提供任何自定义选项供用户定义对其独特安全需求有意义的警报。这些技术限制,加上跨数千万台设备经济高效地管理通知的可扩展性挑战,使得很明显,渐进式的改进是远远不够的——Swann需要一个根本上更智能的方法。
每台摄像机平均每天产生大约20条通知——其中大部分是不相关的——导致客户错过关键的安全事件,许多用户在最初几个月内就禁用了通知。这极大地降低了系统的有效性,凸显了提供仅相关警报的智能过滤的必要性。通过使用协同工作的AWS集成服务,而不是管理多个供应商和自定义集成,Swann的工程团队可以将精力集中在创建新的安全功能上。
为什么选择AWS和Amazon Bedrock
在评估AI合作伙伴时,Swann优先考虑能够可靠扩展的企业级功能。AWS因以下几个关键原因脱颖而出:
企业级AI能力
Swann选择AWS是因为其在规模化部署生成式AI方面的全面、集成的方法。Amazon Bedrock是一个完全托管的服务,通过单个API即可访问多个基础模型,自动处理GPU供应、模型部署和扩展,因此Swann可以在不进行基础设施更改的情况下测试和比较不同模型系列(如Claude和Nova),并根据每种场景(例如,高容量例行筛选、需要详细分析的威胁验证、时间敏感警报和需要细致推理的复杂行为评估)优化速度或准确性。每月约有2.75亿次推理,AWS的按使用付费定价模式,以及使用像Nova Lite这样具有成本效益的模型进行例行分析的能力,实现了成本优化。AWS服务在北美、欧洲和亚太地区提供了低延迟推理,同时为任务关键型安全应用提供了数据驻留合规性和高可用性。
Swann使用的AWS环境包括AWS IoT Core用于设备连接,Amazon Simple Storage Service (Amazon S3)用于可扩展存储和存储视频流,以及AWS Lambda用于根据事件运行代码而无需管理服务器,可从零扩展到数千次执行,并且仅对使用的计算时间收费。Amazon Cognito用于通过安全的登录、多因素身份验证、社交身份集成和临时AWS凭证来管理用户身份验证和授权。Amazon Simple Query Service (Amazon SQS)用于管理消息队列,在流量高峰期间缓冲请求,并在数千个摄像头同时触发时帮助确保可靠处理。
通过利用这些能力来消除管理多个供应商和自定义集成的精力,Swann可以将重点从基础设施转向创新。这种以云为中心的集成将上市时间加快了2个月,同时降低了运营开销,从而能够在数百万设备上经济高效地部署复杂的AI功能。
可扩展性和性能要求
Swann的解决方案需要处理数百万个并发设备(超过1174万台全天候生成帧的摄像头)、可变的*工作负载模式*(晚间和周末活动高峰)、为关键安全事件提供*亚秒级延迟*的实时处理、跨多个地理区域的*全球分发*和一致的性能,以及通过透明定价实现*成本可预测性*(与使用量线性扩展)。Swann发现,Amazon Bedrock和AWS服务为他们提供了两全其美的优势:一个能够处理其巨大规模的全球网络,以及智能成本控制,使他们能够为每种情况选择最合适的模型。
解决方案架构概述与实施
Swann的动态通知系统战略性地使用了Amazon Bedrock中的四种基础模型(Nova Lite、Nova Pro、Claude Haiku和Claude Sonnet),跨越两个关键功能,以平衡性能、成本和准确性。下图所示的架构演示了如何组合AWS服务以使用生成式AI功能创建可扩展、智能的视频分析解决方案,同时优化性能和成本:
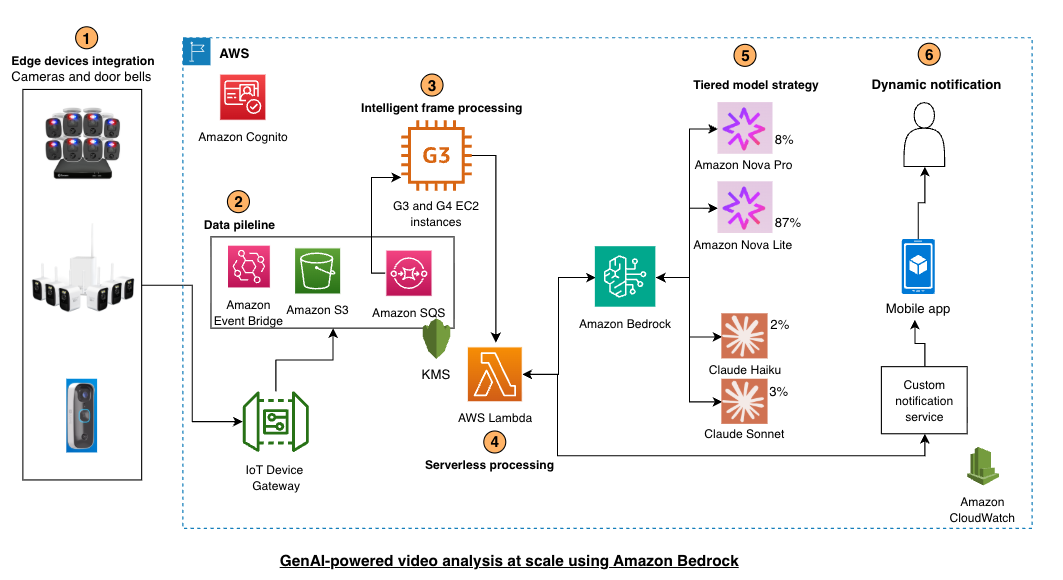
- 边缘设备集成:智能摄像头和门铃通过AWS IoT设备网关连接,提供用于分析的实时视频流。
- 数据管道:视频内容流经Amazon EventBridge、Amazon S3和Amazon SQS,以实现可靠的存储和消息队列。
- 智能帧处理:Amazon Elastic Compute Cloud (Amazon EC2)实例(G3和G4系列)使用计算机视觉库将视频分割成帧,并处理帧选择和过滤以优化处理效率。G3和G4实例是GPU驱动的虚拟服务器,专为视频分析和AI推理等并行处理工作负载设计。与顺序处理任务的传统CPU不同,GPU包含数千个核心,可以同时分析多个视频帧。这意味着Swann可以并发处理来自数千个摄像头的帧而不会出现延迟瓶颈,从而提供近乎实时的安全监控。
- 无服务器处理:Lambda函数调用Amazon Bedrock,并根据用例需求实施模型选择逻辑。
- 分层模型策略:使用具有不同能力的多种模型的经济高效方法。使用Nova Lite进行例行高容量筛选的速度和成本效率,使用Nova Pro进行需要更高准确性验证的潜在威胁的平衡性能,使用Claude Haiku用于时间紧迫警报的超低延迟,以及使用Claude Sonnet用于需要细致推理的复杂行为分析。
- 动态通知:自定义通知服务根据检测结果向移动应用程序提供实时警报。
生成式AI实施的最佳实践
以下最佳实践可以帮助组织在规模化实施类似生成式AI解决方案时优化成本、性能和准确性:
- 理解RPM和Token限制:每分钟请求(RPM)限制定义了每分钟允许的API调用次数,要求应用程序实施队列或重试逻辑以处理高容量工作负载。Token是AI模型处理文本和图像的基本单位,成本按每千个Token计算,因此简洁的提示对于降低规模化成本至关重要。
- 业务逻辑优化:Swann在调用AI模型之前实施智能预筛选(运动检测、基于区域的分析和重复帧消除),将API调用量减少了88%(从17,000降至2,000 RPM)。
- 提示工程和Token优化:Swann通过三种关键策略实现了88%的Token削减(从每个请求的150个减少到18个):
- 优化图像分辨率以减少输入Token,同时保持视觉质量。
- 在基于GPU的EC2实例上部署自定义预筛选模型,在到达Amazon Bedrock之前消除了65%的误报(摆动的树枝、路过的汽车)。
- 设计超简洁的提示,采用结构化响应格式,用机器可解析的键值对(例如:
threat:LOW|type:person|action:delivery)取代冗长的自然语言。Swann的客户调查显示,这些优化不仅降低了延迟和成本,还将威胁检测准确率从89%提高到95%。
- 提示版本控制、优化和测试:Swann使用性能元数据(准确性、成本和延迟)对提示进行版本控制,并在推出前对5-10%的流量进行A/B测试。Swann还使用Amazon Bedrock的提示优化。
- 模型选择和分层策略:Swann根据活动类型选择模型。
- Nova Lite (占请求的87%):处理例行活动的快速筛选,如路过的汽车、宠物和送货人员。其低成本、高吞吐量和亚毫秒级延迟对于速度和效率比精度更重要的、高容量的实时分析至关重要。
- Nova Pro (占请求的8%):当潜在威胁需要更高准确性验证时,从Nova Lite升级。区分送货人员和入侵者,并识别可疑行为模式。
- Claude Haiku (占请求的2%):为“在我...'时通知我'功能提供支持,用于立即通知用户定义的标准。为时间敏感的自定义警报提供超低延迟。
- Claude Sonnet (占请求的3%):处理需要复杂推理的复杂边缘案例。分析多人互动、模糊场景,并提供细致的行为评估。
- 结果:这种智能路由实现了95%的总体准确率,与对所有请求使用Claude Sonnet相比,成本降低了99.7%(从预计的每月210万美元降至6千美元)。关键见解是,将模型能力与任务复杂性相匹配,可以实现经济高效的大规模生成式AI部署,其中业务逻辑预筛选和分层模型选择带来的节省远超模型选择本身。
- 模型蒸馏策略:Swann训练较小、较快的AI模型来模仿较大模型的智能——就像创建一个轻量级版本,它几乎和原版一样智能,但工作速度更快,成本比大模型低。对于新功能,Swann正在探索Nova模型蒸馏技术。它允许知识从更大、更先进的模型转移到更小、更高效的模型。它还有助于优化模型性能以适应特定用例,而无需广泛的带标签训练数据。
- 实施全面监控:使用Amazon CloudWatch跟踪关键性能指标,包括延迟百分位数——p50(中位数响应时间)、p95(捕获大多数用户的最差情况)和p99(识别异常值和系统压力)——以及Token消耗量、每次推理的成本、准确率和限制事件。这些百分位指标至关重要,因为平均延迟可能会掩盖性能问题;例如,200毫秒的平均值可能隐藏着5%的请求耗时超过2秒,这直接影响客户体验。
结论
实施Amazon Bedrock后,Swann立即看到了改进——客户收到的警报更少但更相关。警报量下降了25%,而通知相关性提高了89%,客户满意度提高了3%。该系统可扩展到1174万台设备,p95延迟低于300毫秒,证明了复杂的生成式AI功能可以经济高效地部署在消费类物联网产品中。动态通知(如下所示)提供了情境感知的安全警报。
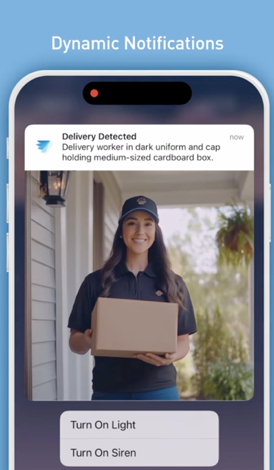
“在我...'时通知我'功能(如下面的视频所示)展示了智能定制。用户使用自然语言定义对他们重要的内容,例如“如果狗进入后院,请通知我”或“如果孩子靠近游泳池,请通知我”,从而实现真正个性化的安全监控。
后续步骤
考虑进行大规模生成式AI部署的组织应从一个清晰、可衡量的业务问题开始,并在全面部署前先对一小部分设备进行试点,从第一天起就通过智能业务逻辑和分层模型选择来实现成本优化。投资于全面监控以实现持续优化,并设计具有优雅降级能力的架构,以验证即使在服务中断期间的可靠性。尽早关注提示工程和Token优化,以帮助实现性能和成本的改进。使用像Amazon Bedrock这样的托管服务来处理基础设施的复杂性,并构建支持未来模型改进和不断发展的AI功能的灵活架构。
探索额外资源
关于作者
 Aman Sharma是AWS的企业解决方案架构师,在ANZ地区为企业零售和供应链客户提供服务。拥有超过21年的咨询、架构和解决方案设计经验,热衷于普及AI和ML,帮助客户设计数据和ML策略。工作之余,他喜欢探索自然和野生动物摄影。
Aman Sharma是AWS的企业解决方案架构师,在ANZ地区为企业零售和供应链客户提供服务。拥有超过21年的咨询、架构和解决方案设计经验,热衷于普及AI和ML,帮助客户设计数据和ML策略。工作之余,他喜欢探索自然和野生动物摄影。
 Surjit Reghunathan是Swann Communications的技术总监,负责领导公司全球物联网安全平台的*技术创新和战略方向*。Surjit在扩展联网设备解决方案方面拥有专业知识,推动AI和机器学习能力在其产品组合中的集成。工作之余,他喜欢长途摩托车骑行和弹吉他。
Surjit Reghunathan是Swann Communications的技术总监,负责领导公司全球物联网安全平台的*技术创新和战略方向*。Surjit在扩展联网设备解决方案方面拥有专业知识,推动AI和机器学习能力在其产品组合中的集成。工作之余,他喜欢长途摩托车骑行和弹吉他。
 Suraj Padinjarute是AWS的技术客户经理,帮助零售和供应链客户最大化其云投资的价值。凭借在数据库管理、应用程序支持和云转型方面超过20年的IT经验,他热衷于赋能客户进行云之旅。工作之余,Suraj喜欢长距离自行车运动和探索户外活动。
Suraj Padinjarute是AWS的技术客户经理,帮助零售和供应链客户最大化其云投资的价值。凭借在数据库管理、应用程序支持和云转型方面超过20年的IT经验,他热衷于赋能客户进行云之旅。工作之余,Suraj喜欢长距离自行车运动和探索户外活动。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区