



📢 转载信息
原文链接:https://machinelearningmastery.com/building-smart-machine-learning-in-low-resource-settings/
原文作者:Nate Rosidi
在本篇文章中,你将学到在计算资源有限、数据不完整以及缺乏工程支持的情况下,构建实用机器学习解决方案的策略。
我们将涵盖的主题包括:
- “低资源”在实践中意味着什么。
- 为什么轻量级模型和简单的流程在受限环境中往往比复杂的方案表现更好。
- 如何处理混乱和缺失的数据,以及在小数据集上仍然有效的简单迁移学习技巧。
让我们开始吧。

Building Smart Machine Learning in Low-Resource Settings
Image by Author
大多数想要构建机器学习模型的人,并没有强大的服务器、干净的数据或一支完整的工程师团队。特别是如果你住在农村地区,经营一家小企业(或者你刚起步,工具有限),你可能无法获得太多资源。
但你仍然可以构建强大、有用的解决方案。
许多有意义的机器学习项目发生在计算能力有限、互联网不可靠的地方,那里的“数据集”与其说是 Kaggle 竞赛,不如说更像一个装满手写笔记的鞋盒。但这同时也是一些最巧妙想法诞生的地方。
在这里,我们将讨论如何在这些环境中实现机器学习,并借鉴真实项目中的经验,包括在 StrataScratch 等平台上看到的一些智能模式。

低资源到底意味着什么
总而言之,在低资源环境中工作可能看起来是这样的:
- 过时或运行缓慢的计算机
- 网络不稳定或没有网络
- 不完整或混乱的数据
- 一个人的“数据团队”(很可能是你)
这些限制可能感觉很有限,但你的解决方案仍然有很大的潜力变得智能、高效,甚至具有创新性。
为什么轻量级机器学习实际上是强大的优势
事实是,深度学习获得了大量关注,但在低资源环境中,轻量级模型是你的最佳选择。逻辑回归、决策树和随机森林听起来可能有点老派,但它们能完成工作。
它们速度快。它们可解释。并且它们在基本硬件上运行得非常好。
此外,当你为农民、店主或社区工作者构建工具时,清晰度至关重要。人们需要信任你的模型,而简单的模型更容易解释和理解。
经典模型常见的成功应用:
- 作物分类
- 预测库存水平
- 设备维护预测
所以,不要追求复杂性。优先考虑清晰度。
将混乱的数据变成魔法:特征工程入门
如果你的数据集有点(或很多)混乱,欢迎加入我们。损坏的传感器、缺失的销售记录、手写笔记……我们都经历过。
以下是如何从混乱的输入中提取意义:
1. 时间特征
即使是时间戳不一致也可以很有用。将其分解为:
- 星期几
- 距离上次事件的时间
- 季节性标志
- 滚动平均值
2. 分类分组
类别太多?你可以将它们分组。与其跟踪每个产品名称,不如尝试“易腐品”、“零食”或“工具”。
3. 基于领域的比率
比率通常优于原始数字。你可以尝试:
- 每英亩的肥料
- 每单位库存的销售额
- 每株植物的水量
4. 稳健的聚合
使用中位数而不是平均值来处理极端异常值(如传感器错误或数据输入错误)。
5. 标志变量
标志是你的秘密武器。添加列,例如:
- “手动修正的数据”
- “传感器电池电量低”
- “估计而非实际”
它们为你的模型提供了重要的上下文。
数据缺失?
数据缺失可能是一个问题,但并非总是如此。它可能是伪装的信息。重要的是要小心谨慎地处理它。
将缺失视为信号
有时,未填写的字段可以讲述一个故事。如果农民跳过某些条目,这可能表明有关他们的情况或优先事项的信息。
坚持简单的插补
使用中位数、众数或前向填充。花哨的多模型插补?如果你的笔记本电脑已经气喘吁吁,就跳过它。
利用领域知识
领域专家通常有明智的规则,例如使用种植季节的平均降雨量或已知的节假日销售下滑。
避免复杂的链条
不要试图用一切来插补一切;这只会增加噪音。定义一些可靠的规则并坚持下去。
小数据?认识迁移学习
这是一个很酷的技巧:你不需要海量数据集就可以从大玩家那里获益。即使是简单的迁移学习形式也能大有裨益。
文本嵌入
有检查说明或书面反馈吗?使用小型预训练嵌入。低成本带来巨大收益。
全局到局部
采用一个全局天气-产量模型,并使用少量本地样本进行调整。线性调整可以产生奇效。
从基准测试中进行特征选择
利用公开数据集来指导应包含哪些特征,特别是如果你的本地数据混乱或稀疏。
时间序列预测
借用全球趋势的季节性模式或滞后结构,并针对你的本地需求进行定制。
真实案例:低资源农业中的智能作物选择
轻量级机器学习的一个有用例子来自一个处理印度真实农业数据的 StrataScratch 项目。

这个项目的目标是推荐适合农民实际条件的作物:混乱的天气模式、不完美的土壤等等。
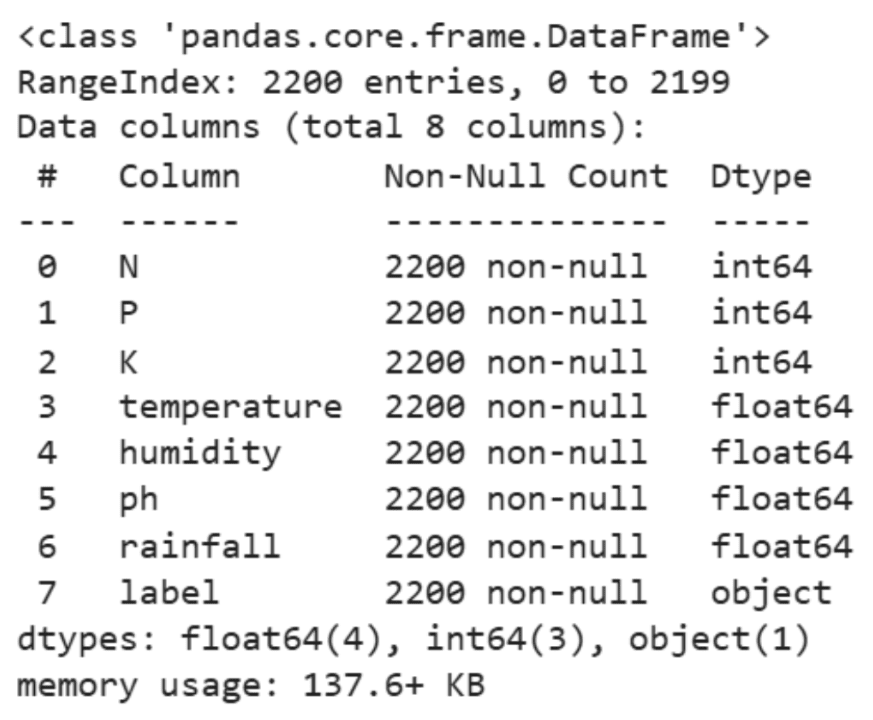
其背后的数据集适中:大约 2,200 行。但它涵盖了重要的细节,如土壤养分(氮、磷、钾)和 pH 值,以及基本的气候信息,如温度、湿度和降雨量。以下是数据样本:

分析有意保持简单,而不是采用深度学习或其他复杂的方法。
我们从一些描述性统计数据开始:
|
1
|
df.info()
|
|
1
|
df.select_dtypes(include=['int64', 'float64']).describe()
|

然后,我们进行一些可视化探索:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# Setting the aesthetic style of the plots
sns.set_theme(style="whitegrid")
# Creating visualizations for Temperature, Humidity, and Rainfall
fig, axes = plt.subplots(1, 3, figsize=(14, 5))
# Temperature Distribution
sns.histplot(df['temperature'], kde=True, color="skyblue", ax=axes[0])
axes[0].set_title('Temperature Distribution')
# Humidity Distribution
sns.histplot(df['humidity'], kde=True, color="olive", ax=axes[1])
axes[1].set_title('Humidity Distribution')
# Rainfall Distribution
sns.histplot(df['rainfall'], kde=True, color="gold", ax=axes[2])
axes[2].set_title('Rainfall Distribution')
plt.tight_layout()
plt.show()
|

最后,我们进行一些 ANOVA 检验,以了解环境因素在不同作物类型之间如何差异:
湿度 ANOVA 分析
|
1
2
3
4
5
6
7
8
9
10
|
# Define crop_types based on your DataFrame 'df'
crop_types = df['label'].unique()
# Preparing a list of humidity values for each crop type
humidity_lists = [df[df['label'] == crop]['humidity'] for crop in crop_types]
# Performing the ANOVA test for humidity
anova_result_humidity = f_oneway(*humidity_lists)
anova_result_humidity
|

降雨量 ANOVA 分析
|
1
2
3
4
5
6
7
8
9
10
|
# Define crop_types based on your DataFrame 'df' if not already defined
crop_types_rainfall = df['label'].unique()
# Preparing a list of rainfall values for each crop type
rainfall_lists = [df[df['label'] == crop]['rainfall'] for crop in crop_types_rainfall]
# Performing the ANOVA test for rainfall
anova_result_rainfall = f_oneway(*rainfall_lists)
anova_result_rainfall
|
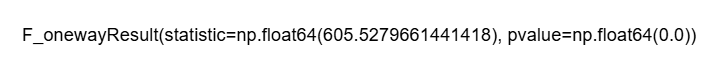
温度 ANOVA 分析
|
1
2
3
4
5
6
7
8
9
10
|
# Ensure crop_types is defined from your DataFrame 'df'
crop_types_temp = df['label'].unique()
# Preparing a list of temperature values for each crop type
temperature_lists = [df[df['label'] == crop]['temperature'] for crop in crop_types_temp]
# Performing the ANOVA test for temperature
anova_result_temperature = f_oneway(*temperature_lists)
anova_result_temperature
|
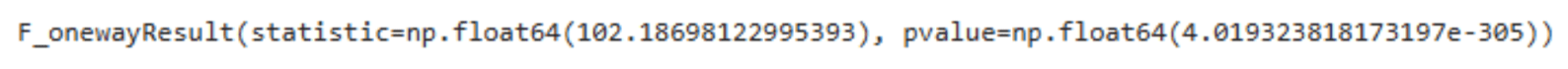
这个小规模、低资源的项目反映了农村农业中的现实挑战。我们都知道天气模式不遵循规则,气候数据可能不稳定或不一致。所以,我们没有使用复杂的模型来解决问题并希望它能自行解决,而是手动深入研究了数据。
也许这种方法最有价值的方面是它的可解释性。农民不寻求不透明的预测;他们想要可以采取行动的指导。像“这种作物在高湿度下表现更好”或“那种作物更喜欢干燥条件”这样的陈述将统计发现转化为实际决策。
整个工作流程非常轻量级。没有花哨的硬件,没有昂贵的软件,只有可靠的工具,如 pandas、Seaborn 和一些基本的统计测试。所有这些都在普通的笔记本电脑上顺利运行。
核心分析步骤使用 ANOVA 来检查湿度或降雨量等环境条件在作物类型之间是否存在显著差异。
在许多方面,这捕捉了低资源环境中机器学习的精神。技术保持基于现实、计算温和且易于解释,但它们仍然能提供深刻的见解,帮助人们做出更明智的决定,即使没有先进的基础设施。
致低资源环境下的有志数据科学家
你可能没有 GPU。你可能在使用免费套餐工具。你的数据可能看起来像一个缺少零件的拼图。
但关键是:你正在学习许多人忽略的技能:
- 真实世界的数据清理
- 基于直觉的特征工程
- 通过可解释的模型建立信任
- 聪明地工作,而不是炫耀
优先考虑以下几点:
- 清晰、一致的数据
- 有效的经典模型
- 周到的特征
- 简单的迁移学习技巧
- 清晰的笔记和可复现性
最终,这就是能造就优秀数据科学家的工作。
结论
Image by Author
在低资源机器学习环境中工作是可能的。它要求你富有创造力并对你的使命充满热情。关键在于从噪音中找到信号,并解决那些能让人们生活更轻松的实际问题。
在本篇文章中,我们探讨了轻量级模型、智能特征、对缺失数据的诚实处理以及对现有知识的巧妙重用,如何在这种情况下帮助你取得进展。
你有什么想法?你是否曾经在低资源环境下构建过解决方案?
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区