



📢 转载信息
原文作者:Madhavi Evana, Dan Kolodny, and Fahim Sajjad
如果您希望提升内容理解力和搜索能力,音频嵌入(Audio Embeddings)提供了一种强大的解决方案。在本文中,您将学习如何使用 Amazon Nova 多模态嵌入(Multimodal Embeddings),将音频内容转化为可搜索的智能数据,捕捉音调、情感、音乐特征以及环境声等声学特征。
在大型音频库中查找特定内容面临着严峻的技术挑战。传统的搜索方法(如手动转录、元数据标记和语音转文字)在处理口语词汇时效果显著,但却忽略了声学属性。音频嵌入弥补了这一差距。它们将音频表示为高维空间中的稠密数值向量,这些向量编码了语义和声学属性,使您能够执行语义搜索、匹配相似音频,并根据声音本身(而非仅凭标签)对内容进行自动分类。
理解音频嵌入:核心概念
音频内容的向量表示
可以将音频嵌入想象成声音的坐标系统。正如 GPS 坐标可以精确定位地球上的地点,嵌入将音频内容映射到高维空间中的特定点。Amazon Nova 提供四种维度选择:3,072(默认)、1,024、384 或 256。每个嵌入都是一个 float32 数组。
相似度度量:当您想要查找相似音频时,可以计算两个嵌入 v₁ 和 v₂ 之间的余弦相似度:
similarity = (v₁ · v₂) / (||v₁|| × ||v₂||)音频处理架构与工作流
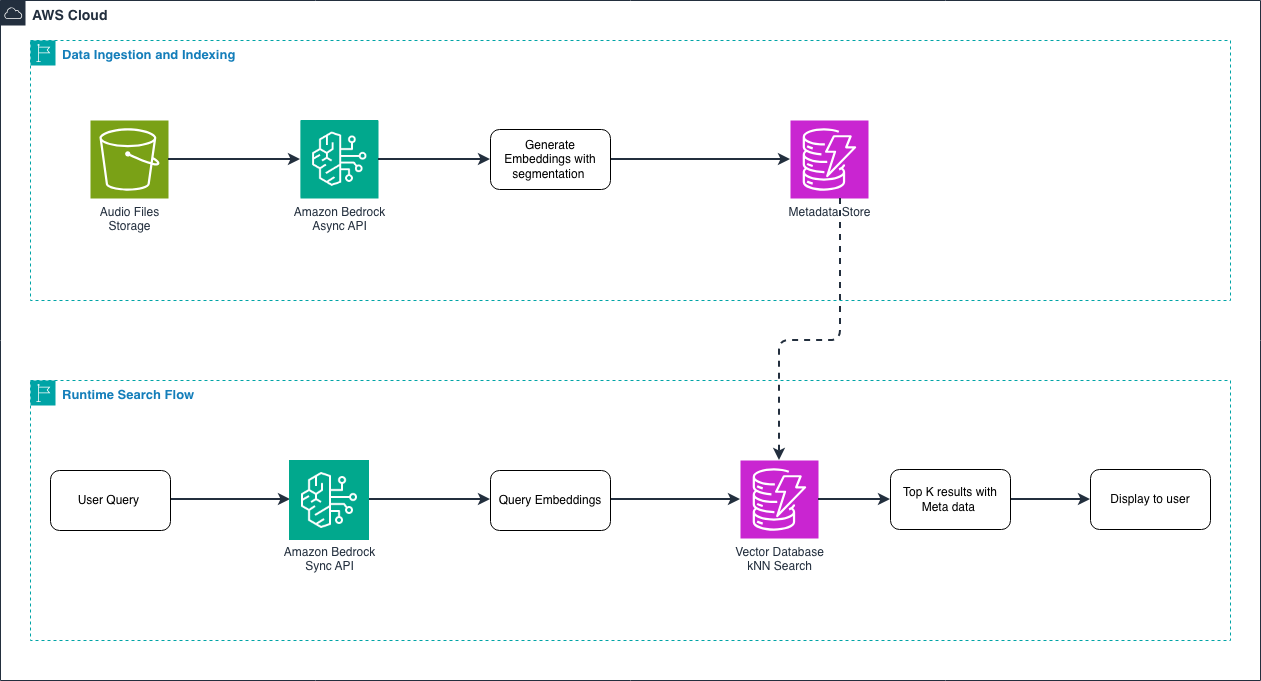
图 1 – 端到端音频嵌入工作流
音频嵌入的工作流分为两个主要阶段:
- 数据摄取与索引:您将音频文件上传至 Amazon S3,通过异步 API 生成嵌入。对于超过 30 秒的音频,模型会自动将其分割并添加时间戳元数据,存储于向量数据库中。
- 实时搜索:当用户搜索时(无论是文本查询“轻快的爵士钢琴”还是音频片段),系统通过同步 API 生成查询嵌入,并在向量数据库中执行 k-NN 搜索,在毫秒级时间内返回结果。
API 操作与生产应用
Amazon Nova 提供同步 API 满足实时搜索的低延迟需求,以及异步/批量 API 用于处理大规模数据索引。对于超过 30 秒的长音频文件(如数小时的播客),可以通过 segmentationConfig 参数进行切分,获取带有时间戳的精确片段,从而实现对特定时间点的搜索。
结论
在本文中,我们探讨了 Amazon Nova 多模态嵌入如何通过将音频表示为捕获声学与语义属性的高维向量,从而实现超越传统文本搜索的深度理解。这种方法不仅优化了呼叫中心分析、媒体搜索和内容发现等场景,还允许用户通过自然语言查询(如“寻找听起来愤怒的发言”)精准定位音频片段,极大提升了音频档案的智能化管理水平。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区