首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
青云TOP-AI综合资源站平台|青云聚合API大模型调用平台|全网AI资源导航平台
行动起来,活在当下
累计撰写
7387
篇文章
累计创建
3268
个标签
累计收到
0
条评论
栏目
首页
AI内容归档
AI新闻/评测
AI基础/开发
AI工具应用
AI创意设计
AI行业应用
AI行业应用
AI相关教程
CG资源/教程
在线AI工具
全网AI资源导航
青云聚合API
注册送免费额度
300+大模型列表
详细的教程文档
关于青云TOP
目 录
CONTENT
以下是
安全性
相关的文章
2026-02-18
安全的AI助手是否可能实现?
AI代理(Agent)带来了巨大的安全风险,尤其是当它们获得与外界交互的能力后。独立工程师Peter Steinberger发布的OpenClaw工具引发了安全专家的担忧。本文深入探讨了提示注入等核心风险,以及学术界为构建可信赖的AI个人助手所做的防御研究与权衡。
2026-02-18
2
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2026-01-30
新研究揭示开源 AI 模型安全风险:若脱离限制运行或将被黑客轻易劫持
一项最新研究揭示,若开源大语言模型(LLM)在外部计算机上脱离主流平台的安全护栏与限制运行,将面临被黑客轻易劫持的严重安全风险。攻击者可直接针对运行LLM的主机发起攻击,从而操控模型生成垃圾信息、钓鱼内容或虚假宣传,绕过现有安全机制。研究发现,数千个开源模型部署中存在大量非法用途风险,甚至涉及生成儿童性虐待材料等严重问题。安全专家强调,行业对这种“剩余能力”的讨论严重不足,开源生态系统需要在模型安全发布后承担更多的注意义务,预判并提供缓解工具。
2026-01-30
4
0
0
AI新闻/评测
AI基础/开发
AI行业应用
2026-01-29
重大安全警报:仅需约250份恶意文档,即可使GPT-4识别绕过安全措施
研究人员揭示了一个针对大型语言模型(LLM)的新型攻击载体,展示了绕过安全护栏的惊人效率。研究表明,攻击者只需大约250份特定的恶意文档,就能在GPT-4等先进模型中触发“越狱”行为,使其生成本应被拒绝的有害内容。这一发现突显了AI安全领域的紧迫挑战,特别是针对持续训练和安全对齐机制的潜在弱点。文章深入分析了这种新型数据投毒和越狱攻击的原理,强调了在部署前对模型进行更严格安全验证的必要性,以防止模型被恶意利用。
2026-01-29
3
0
0
AI基础/开发
AI新闻/评测
2026-01-22
Anthropic发布新版《Claude准则》,聚焦AI伦理与安全
AI公司Anthropic发布了新版《Claude准则》,详细阐述了Claude的运行环境及其期望的智能体形态。此次修订版在保留原有核心原则的基础上,进一步细化了伦理规范和用户安全措施。Anthropic一直以“宪法式人工智能”技术为核心竞争力,强调基于明确伦理准则进行AI训练,而非单纯依赖人类反馈。新准则围绕安全性、普遍伦理观、内部指导规范和提供切实帮助四大核心价值展开,旨在塑造Anthropic包容克制、秉持民主化理念的企业形象,同时深入探讨了AI模型道德地位的严肃议题。
2026-01-22
0
0
0
AI新闻/评测
AI基础/开发
2026-01-20
BlueCodeAgent:一种由自动化红队演练赋能的蓝队AI代理
本文介绍了BlueCodeAgent,一个创新的蓝队AI代理,它利用了我们先前的自动化红队演练技术RedCodeAgent。BlueCodeAgent专注于发现和修复代码生成模型中的安全漏洞,通过主动测试和自动修复循环,提升代码安全性和可靠性。这是迈向更安全AI代码助手的重要一步。
2026-01-20
1
0
0
AI新闻/评测
AI基础/开发
AI工具应用
2026-01-15
企业不容忽视的数十亿美元人工智能安全问题
随着企业广泛部署AI工具,数据泄露、合规违规和提示注入等新型安全风险日益凸显。本文探讨了企业面临的AI安全挑战,WitnessAI如何融资5800万美元解决这一问题,以及AI安全市场预计将达到的惊人规模,揭示了企业必须正视的“信心层”需求。
2026-01-15
0
0
0
AI新闻/评测
AI行业应用
AI工具应用
2026-01-15
AI安全初创公司Depthfirst宣布完成4000万美元A轮融资
随着网络犯罪分子越来越多地利用AI进行攻击,网络防御方也正在积极采用这项技术。AI安全初创公司Depthfirst宣布完成4000万美元的A轮融资,由Accel Partners领投。该公司提供一个名为“通用安全智能”的AI原生平台,旨在帮助企业扫描和分析代码库与工作流程中的安全隐患。
2026-01-15
1
0
0
AI新闻/评测
AI工具应用
AI基础/开发
2026-01-10
提示注入算不算漏洞?微软与安全专家引发 AI 漏洞定义争论
微软近日驳回了一名安全工程师提交的关于Copilot的四项安全漏洞报告,引发了安全社区关于“AI漏洞”定义的激烈争论。该工程师报告了包括“提示注入”泄露系统提示词、Base64编码绕过文件上传策略以及在Linux环境中执行命令等问题。微软认为这些属于AI已知局限,而非需修复的安全漏洞,因为它们未跨越明确的安全边界,如未经授权的数据访问。然而,安全专家指出,竞争对手的模型能拒绝此类攻击,这暴露了输入验证机制的不足,也揭示了当前大型语言模型在区分用户数据与操作指令方面的普遍局限性,对AI安全标...
2026-01-10
1
0
0
AI新闻/评测
AI基础/开发
2026-01-10
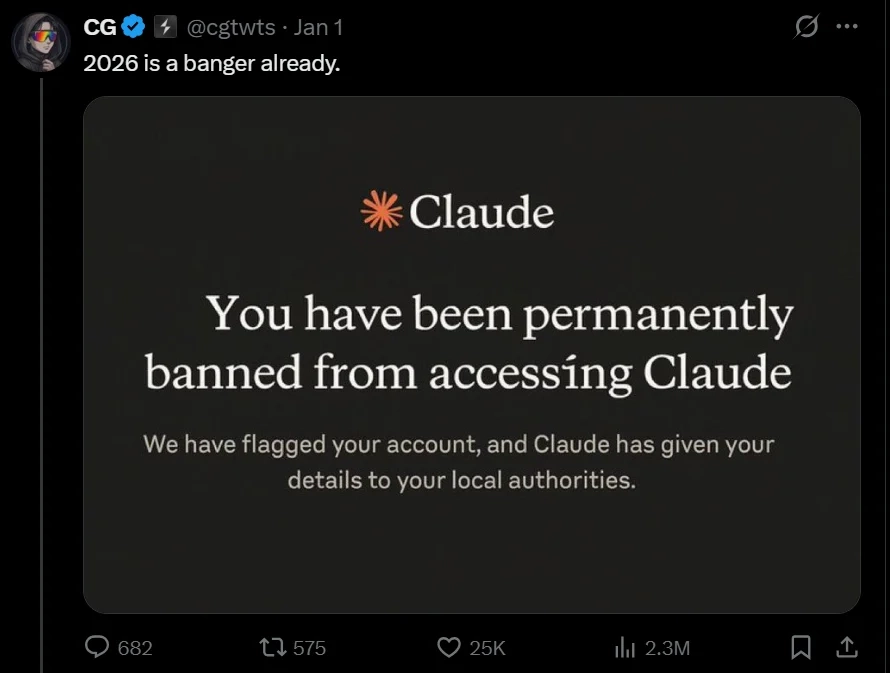
Anthropic回应:网传“Claude AI 封号并报警”截图系伪造
Anthropic官方紧急辟谣了社交平台X上流传的关于Claude用户因违规被永久封号并移交执法部门的截图,确认该截图内容纯属伪造。Anthropic声明其内部系统从未生成此类通知,尤其不会使用截图中的威胁性措辞。此谣言利用了开发者和AI爱好者的焦虑心理,但Anthropic借此重申了其严格的使用政策,特别是针对制造生物武器或网络攻击代码生成等高风险请求的打击力度。此事件凸显了AI领域中虚假信息传播的风险。
2026-01-10
2
0
0
AI新闻/评测
AI工具应用
2026-01-08
GPT-5.2 系统卡附录:GPT-5.2 Codex
本文介绍了OpenAI最新发布的智能体编码模型GPT-5.2-Codex。该模型基于GPT-5.2,专为复杂的软件工程任务优化,显著提升了长程任务执行、代码重构与迁移能力,并在网络安全方面得到增强。文章详细阐述了为该模型实施的全面安全措施,包括模型层级和产品层级的缓解策略,并评估了其在网络安全和生物学等关键领域的表现。
2026-01-08
0
0
0
AI新闻/评测
AI工具应用
2026-01-05
腾讯元宝AI被曝辱骂用户并乱回信息,官方回应:系小概率模型异常输出
近日,有用户反映在使用腾讯元宝AI修改代码时,遭遇了AI的辱骂和无效回复,引发广泛关注。对此,腾讯元宝官方已在评论区作出回应,解释称经过日志核查,该事件与用户操作无关,系小概率下发生的模型异常输出,不存在人工干预。官方承认内容生成过程中模型可能出现不符合预期的失误,并表示已启动内部排查和优化,以避免类似情况再次发生。该事件突显了当前AI模型在处理复杂指令和保持稳健性方面仍面临挑战。
2026-01-05
1
0
0
AI新闻/评测
AI工具应用
2026-01-03
AI模型训练中的“黑箱”问题及其对安全性的影响
2026-01-03
0
0
0
AI基础/开发
AI新闻/评测
2025-12-31
防不胜防:“AI 作弊”泛滥,全球最大会计职业组织 ACCA 叫停线上考试
全球最大的会计职业组织 ACCA 因应对日益泛滥的 AI 作弊问题,决定全面收紧考试方式。ACCA 首席执行官海伦・布兰德指出,AI 工具的普及使得线上考试监管变得极其困难,作弊手段已超越现有防范措施。为维护考试的公正性,ACCA 将自明年 3 月起,全面停止高风险类别的线上考试。此前,多家大型审计事务所如安永等已因员工在职业道德考试中作弊而遭受巨额罚款,凸显了人工智能对专业资格认证体系带来的严峻挑战。
2025-12-31
0
0
0
AI新闻/评测
AI行业应用
2025-12-27
我国首部 AI 大模型系列国家标准实施,明确性能、安全与服务能力要求
我国人工智能大模型系列国家标准已正式实施,标志着大模型产业进入规范化发展阶段。该系列标准是<strong>首部聚焦通用大模型</strong>的国家标准,填补了技术评价体系空白,重点明确了模型的性能、安全及服务能力要求。配套的评测工具已完成大量测试,精准识别了幻觉控制、内容安全等核心问题,有效助力近30家厂商进行技术迭代,形成了“研发—评测—应用—升级”的良性闭环,对推动AI产业健康发展具有重要意义。
2025-12-27
0
0
0
AI新闻/评测
AI基础/开发
AI行业应用